Aws Hadoop
Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath.
Aws hadoop. Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath. Apache Hadoop Installation and Cluster setup on AWS Hadoop cluster on AWS setup, In this tutorial one can easily know the information about Apache Hadoop Installation and Cluster setup on AWS which are available and are used by most of the Hadoop developers. Amazon Web Services (AWS) is the best option for this use case AWS provides a managed solution for Hadoop called Elastic Map Reduce (EMR) EMR allows developers to quickly start Hadoop clusters,.
In a very short span of time Apache Hadoop has moved from an emerging technology to an established solution for Big Data problems faced by today’s enterprises Also, from its launch in 06, Amazon Web Services (AWS) has become synonym to Cloud ComputingCIA’s recent contract with Amazon to build a private cloud service inside the CIA’s data centers is the proof of growing popularity. It’s a special Hadoop FileSystem implementation which recognizes writes to _temporary paths and translate them to writes to the base directory As well as translating the write operation, it also supports a getFileStatus() call on the original path, returning details on the file at the final destination. In a very short span of time Apache Hadoop has moved from an emerging technology to an established solution for Big Data problems faced by today’s enterprises Also, from its launch in 06, Amazon Web Services (AWS) has become synonym to Cloud Computing.
Hadoop Market Will Touch A New Level In The Upcoming Year Amazon Web Services, Cloudera, Inc, Dell, Hortonworks, HPE New Report On the Hadoop Market Hadoop Market Report 27 is a professional and indepth study on the current state of the global Hadoop Market with a focus on the regional Market. Apache Hadoop is an opensource Java software framework that supports massive data processing across a cluster of instances It can run on a single instance or thousands of instances. AWS ProServe Hadoop Cloud Migration for Property and Casualty Insurance Leader Our client is a leader in property and casualty insurance, group benefits and mutual funds With more than 0 years of expertise, the company is widely recognized for its service excellence, sustainability practices, trust and integrity.
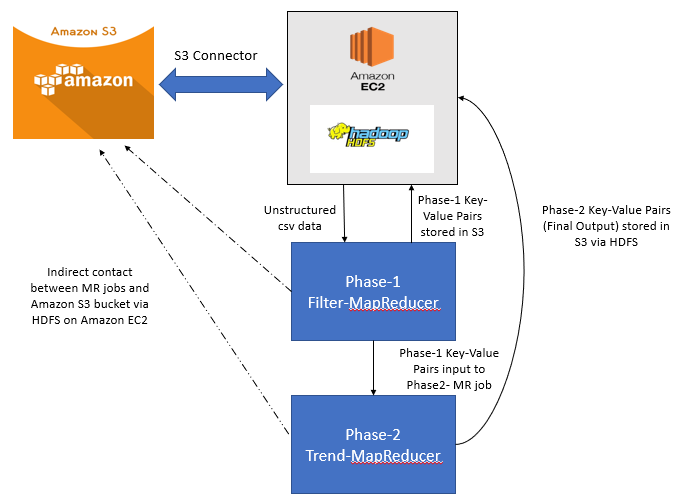
The aws_profile that is used in your local `~/aws/credentials` file ##### terraform_s3_bucket The terraform state information will be maintained in the specified s3 bucket Make sure the aws_profile has write access to the s3 bucket ##### ssh_key_pair For hadoop provisioning, aws_hadoop needs to connect to hadoop nodes using SSH. In this article, I will show you an interesting Automation in which we will Setup the Hadoop Cluster (HDFS) on top of AWS Cloud (EC2) and we will do everything using a tool called Ansible which is. It utilizes a hosted Hadoop framework running on the webscale infrastructure of Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3).
The AWS SDK JARs change their signature enough between releases that the only way to safely update the AWS SDK version is to recompile Hadoop against the later version The sole fix is to use the same version of the AWS SDK with which Hadoop was built This can also be caused by having more than one version of an AWS SDK JAR on the classpath. For hadoop provisioning, aws_hadoop needs to connect to hadoop nodes using SSH The specified `ssh_key_pair` will allow the hadoop ec2's to be created with the public key If So make sure your machine has the private key in your `~/ssh/` directory. As opposed to AWS EMR, which is a cloud platform, Hadoop is a data storage and analytics program developed by Apache You can think of it this way if AWS EMR is an entire car, then Hadoop is akin to the engine.
Apache Spark on EMR EMR (Elastic Map Reduce) is an Amazonmanaged Hadoop distribution It runs on EC2 nodes and the hosts are initialized by installing data processing libraries (like Apache. Apache™ Hadoop® is an open source software project that can be used to efficiently process large datasets Instead of using one large computer to process and store the data, Hadoop allows clustering commodity hardware together to analyze massive data sets in parallel. This is a step by step guide to install a Hadoop cluster on Amazon EC2 I have my AWS EC2 instance ecapsoutheast1computeamazonawscom ready on which I will install and configure Hadoop, java 17 is already installed In case java is not installed on you AWS EC2 instance, use below commands.
Hadoop is one of the most mature and wellknown opensource big data frameworks on the market Sprung from the concepts described in a paper about a distributed file system created at Google and implementing the MapReduce algorithm made famous by Google, Hadoop was first released by the opensource community in 06. Hadoop is suitable for Massive Offline batch processing, by nature cannot be and should not be used for online analytic Unlikely, Amazon Redshift is built for Online analytical purposes * Massively parallel processing * Columnar data storage. Amazon Web Services (AWS) is a Public Cloud platform from a proprietary company, Amazon Hadoop is an opensource Javabased technology and Big Data processing, storing stack from Apache Software Foundation.
Amazon EMR is a managed service that makes it fast, easy, and costeffective to run Apache Hadoop and Spark to process vast amounts of data Amazon EMR also supports powerful and proven Hadoop tools such as Presto, Hive, Pig, HBase, and more. The Hadoop Credential API can be used to manage access to S3 in a more finegrained way The first step is to create a local JCEKS file in which to store the AWS Access Key and AWS Secret Key values. Faster timetoinsight AWS provides the greatest flexibility for deploying Hadoop, which excels at largescale data management Cloudera users can now bypass prolonged infrastructure selection and procurement processes to rapidly implement Cloudera, immediately realizing tangible business value from their data.
This tutorial illustrates how to connect to the Amazon AWS system and run a Hadoop/MapReduce program on this service The first part of the tutorial deals with the wordcount program already covered in the Hadoop Tutorial 1 The second part deals with the same wordcount program, but this time we'll provide our own version. Thanks for A Amazon Web Services (AWS) is a Public Cloud platform from a proprietary company, Amazon Hadoop is an opensource Javabased technology and Big Data processing, storing stack from Apache Software Foundation Both are different If. Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath.
It utilizes a hosted Hadoop framework running on the webscale infrastructure of Amazon Elastic Compute Cloud (Amazon EC2) and Amazon Simple Storage Service (Amazon S3). Running Hadoop on Amazon EC2 Amazon EC2 (Elastic Compute Cloud) is a computing service One allocates a set of hosts, and runs one's application on them, then, when done, deallocates the hosts Billing is hourly per host. Running Hadoop on Amazon EC2 Amazon EC2 (Elastic Compute Cloud) is a computing service One allocates a set of hosts, and runs one's application on them, then, when done, deallocates the hosts Billing is hourly per host.
The following tables list the version of Hadoop included in each release version of Amazon EMR, along with the components installed with the application For component versions in each release, see the Component Version section for your release in Amazon EMR 5x Release Versions or Amazon EMR 4x Release Versions Did this page help you?. AWS ProServe Hadoop Cloud Migration for Property and Casualty Insurance Leader Our client is a leader in property and casualty insurance, group benefits and mutual funds With more than 0 years of expertise, the company is widely recognized for its service excellence, sustainability practices, trust and integrity. AWS is here to help you migrate your big data and applications Our Apache Hadoop and Apache Spark to Amazon EMR Migration Acceleration Program provides two ways to help you get there quickly and with confidence.
Hadoop is an Apache open source project that is used to efficiently process large datasets It allows clustering commodity hardware together to analyze massive data sets in parallel, instead of using one large computer to process and store the data. AWS is here to help you migrate your big data and applications Our Apache Hadoop and Apache Spark to Amazon EMR Migration Acceleration Program provides two ways to help you get there quickly and with confidence. AWS’ core analytics offering EMR (a managed Hadoop, Spark and Presto solution) helps set up an EC2 cluster and provides integration with various AWS services Azure also supports both NoSQL and relational databases and as well Big Data through Azure HDInsight and Azure table.
There are a lot of topics to cover, and it may be best to start with the keystrokes needed to standup a cluster of four AWS instances running Hadoop and Spark using Pegasus Clone the Pegasus repository and set the necessary environment variables detailed in the ‘ Manual ’ installation of Pegasus Readme. In this video we will compare HDFS vs AWS S3, and compare and contrast scenarios where S3 is better than HDFS and scenarios where HDFS is better than Amazon. Let’s take an example to configure a 4Node Hadoop cluster in AWS and do a cost comparison EMR costs $0070/h per machine (m3xlarge), which comes to $2, for a 4Node cluster (4 EC2 Instances 1 master3 Core nodes) per year The Same size Amazon EC2 cost $0266/hour, which comes to $9364 per year.
Amazon EMR is the industryleading cloud big data platform for processing vast amounts of data using open source tools such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto. Hadoop daemon settings are different depending on the EC2 instance type that a cluster node uses The following tables list the default configuration settings for each EC2 instance type To customize these settings, use the hadoopenv configuration classification For more information, see Configuring Applications. Hadoop is one of the most mature and wellknown opensource big data frameworks on the market Sprung from the concepts described in a paper about a distributed file system created at Google and implementing the MapReduce algorithm made famous by Google, Hadoop was first released by the opensource community in 06.
One of the really great things about Amazon Web Services (AWS) is that AWS makes it easy to create structures in the cloud that would be extremely tedious and timeconsuming to create onpremises For example, with Amazon Elastic MapReduce (Amazon EMR) you can build a Hadoop cluster within AWS without the expense and hassle of provisioning. On AWS, you can use an AWS native service like Amazon EMR for the Hadoop cold tier storage location To use Amazon EMR with SAP HANA, see DLM on Amazon Elastic Map Reduce documentation from SAP Figure 5 SAP HANA with Amazon EMR for cold tier Cold Tier Options for SAP BW. To access EMR Local, use only linux cli commands while to access EMR HDFS we need to add “hadoop fs” and “” as shown above In AWS, “hive” command is used in EMR to launch Hive CLI as.
For hadoop provisioning, aws_hadoop needs to connect to hadoop nodes using SSH The specified `ssh_key_pair` will allow the hadoop ec2's to be created with the public key If So make sure your machine has the private key in your `~/ssh/` directory. Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath. Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
Faster timetoinsight AWS provides the greatest flexibility for deploying Hadoop, which excels at largescale data management Cloudera users can now bypass prolonged infrastructure selection and procurement processes to rapidly implement Cloudera, immediately realizing tangible business value from their data. Hadoop MapReduce is a programming model for processing big data sets with a parallel, distributed algorithm Developers can write massively parallelized operators, without having to worry about work distribution, and fault tolerance However, a challenge to MapReduce is the sequential multistep process it takes to run a job. Following are list of players Amazon Web Services (AWS), Cloudera, Cray, Google Cloud Platform, Hortonworks, Huawei, IBM, MapR Technologies, Microsoft, Oracle, Qubole, Seabox, Teradata, Transwarp 2) What is the expected Market size and growth rate of the Hadoop Distribution market for the period 1925?.
AWS is here to help you migrate your big data and applications Our Apache Hadoop and Apache Spark to Amazon EMR Migration Acceleration Program provides two ways to help you get there quickly and with confidence. Hadoop is a framework that helps processing large data sets across multiple computers It includes Map/Reduce (parallel processing) and HDFS (distributed file system) Hive is a data warehouse built on top of HDFS and Map/Reduce It provides a SQLlike query engine that converts queries into Map/Reduce jobs and run them on the cluster. Browse files in S3 and Hdfs — “hadoop fs cat” can be used to browse data in S3 and EMR Hdfs as below Here head along with “” character is used to limit the number of rows Browse S3 data.
The objective of the report is to define, describe, and forecast the Hadoop big data analytics market size based on component, organization size, deployment mode, business function, vertical, and. Let’s take an example to configure a 4Node Hadoop cluster in AWS and do a cost comparison EMR costs $0070/h per machine (m3xlarge), which comes to $2, for a 4Node cluster (4 EC2 Instances 1 master3 Core nodes) per year The Same size Amazon EC2 cost $0266/hour, which comes to $9364 per year. The AWS SDK JARs change their signature enough between releases that the only way to safely update the AWS SDK version is to recompile Hadoop against the later version The sole fix is to use the same version of the AWS SDK with which Hadoop was built This can also be caused by having more than one version of an AWS SDK JAR on the classpath.
A key part of the Workshop is discussing your current onpremises Apache Hadoop/Spark architecture, your workloads, and your desired future architecture Complete the form and one of our technical experts will contact you to confirm the best date and time for your team to attend the online workshop. Following are list of players Amazon Web Services (AWS), Cloudera, Cray, Google Cloud Platform, Hortonworks, Huawei, IBM, MapR Technologies, Microsoft, Oracle, Qubole, Seabox, Teradata, Transwarp 2) What is the expected Market size and growth rate of the Hadoop Distribution market for the period 1925?. AWS Security Group (without security 😇) Finally, click on Review and Launch We need to create a key pair in order to connect to our instance securely, here through SSH Select Create a new key pair from the first dropbox, give a name to the key pair (eg hadoopec2cluster) and download it.
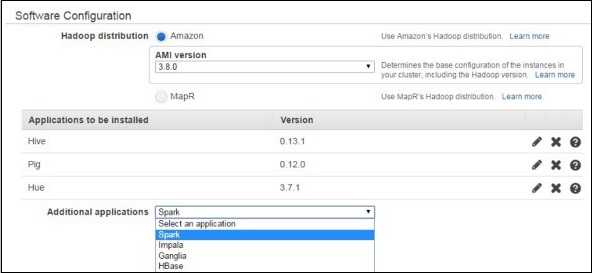
AWS Documentation Amazon EMR Documentation Amazon EMR Release Guide Apache Hive Hive is an opensource, data warehouse, and analytic package that runs on top of a Hadoop cluster.
Map Reduce With Amazon Ec2 And S3 By Sanchit Gawde Medium
How To Install Apache Hadoop Cluster On Amazon Ec2 Tutorial Edureka

How To Create Hadoop Cluster With Amazon Emr Edureka
Aws Hadoop のギャラリー
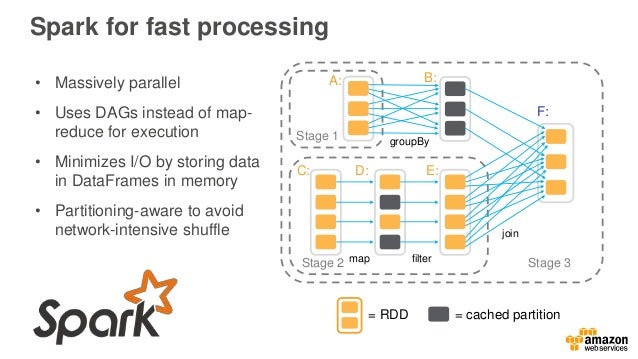
Apache Spark And The Hadoop Ecosystem On Aws

Running Pagerank Hadoop Job On Aws Elastic Mapreduce The Pragmatic Integrator

1 Introduction To Amazon Elastic Mapreduce Programming Elastic Mapreduce Book

4 4 What Is Amazon Emr Cbtuniversity
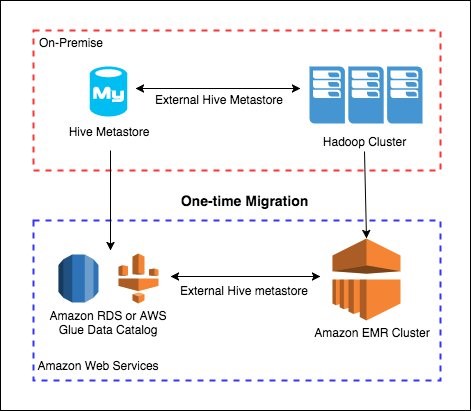
Migrate And Deploy Your Apache Hive Metastore On Amazon Emr Aws Big Data Blog

Hadoop Tutorial 3 3 How Much For 1 Month Of Aws Mapreduce Dftwiki

Aws Proserve Hadoop Cloud Migration For Property And Casualty Insurance Leader Softserve
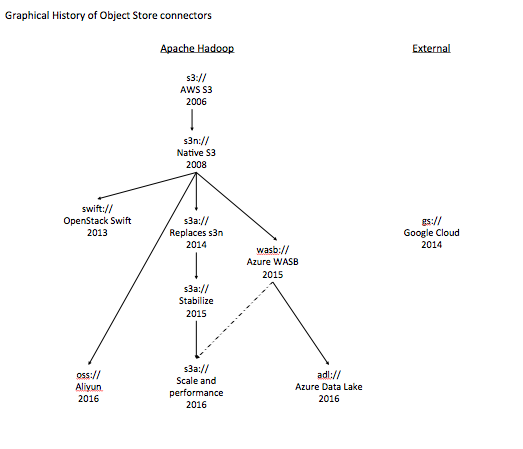
The History Of Apache Hadoop S Support For Amazon S3 Dzone Big Data
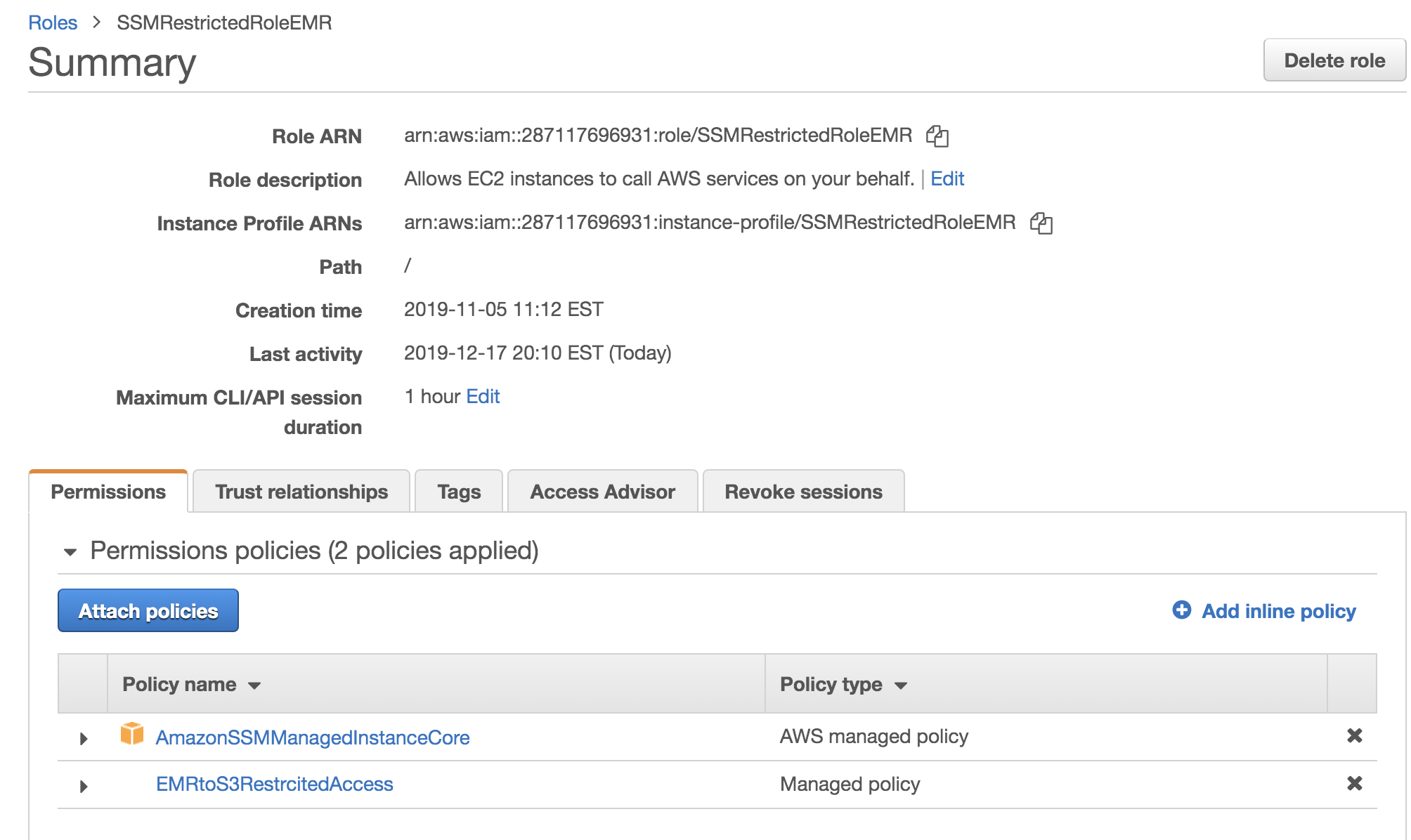
Using Aws Systems Manager Run Command To Submit Spark Hadoop Jobs On Amazon Emr Aws Management Governance Blog
How To Create A Hadoop Cluster In Aws Virtualization Review

Migrating Hdp Cluster To Amazon Emr To Save Costs
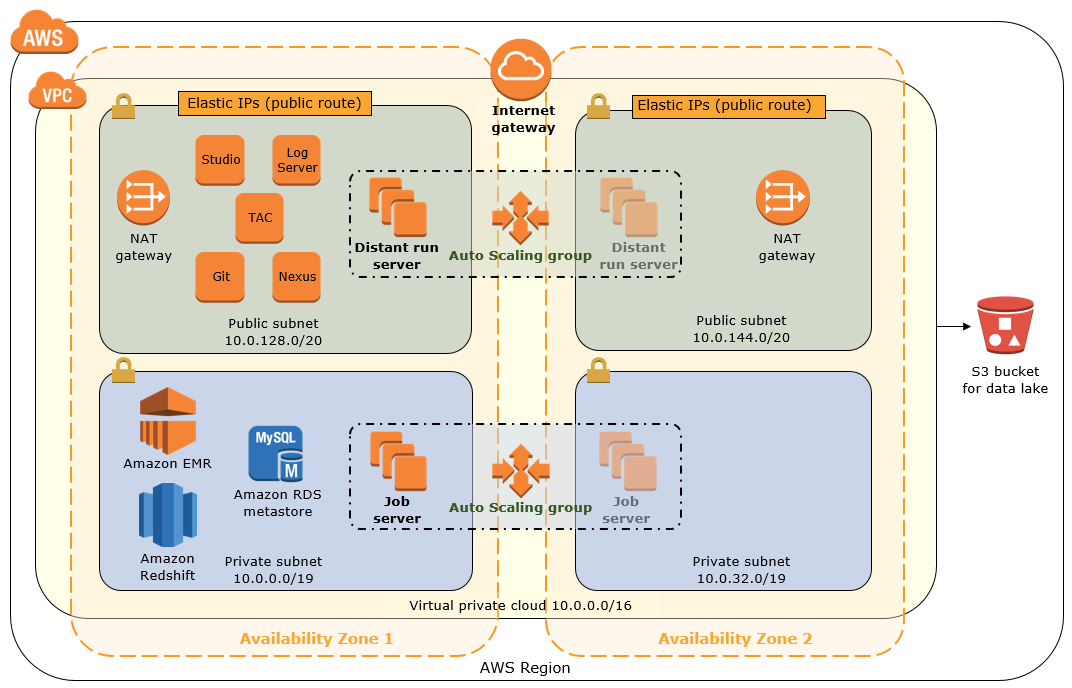
Data Lake With Talend Big Data Platform Quick Start
Aws Quickstart S3 Amazonaws Com Quickstart Cloudera Doc Cloudera Edh On Aws Pdf

Introduction To Amazon Emr The Little Steps

Running Pagerank Hadoop Job On Aws Elastic Mapreduce The Pragmatic Integrator
Www Netapp Com Media Tr 4529 Pdf

Amazon Elastic Mapreduce Emr Exam Tips Aws Certification
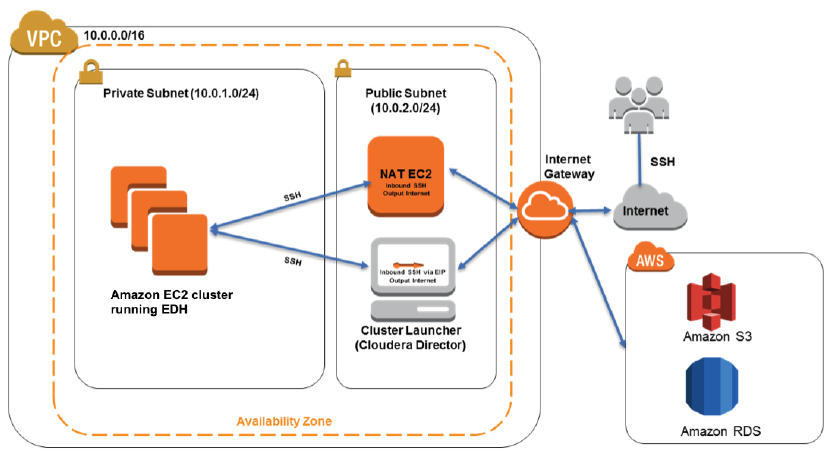
New Aws Quick Start Cloudera Enterprise Data Hub Aws News Blog

Using Hadoop And Spark With Aws Emr

How To Run A Hive Script On An Aws Hadoop Cluster Virtualization Review

Accessing A Million Songs With Hive And Hadoop On Aws Inspiration Information

Two Choices 1 Amazon Emr Or 2 Hadoop On Ec2
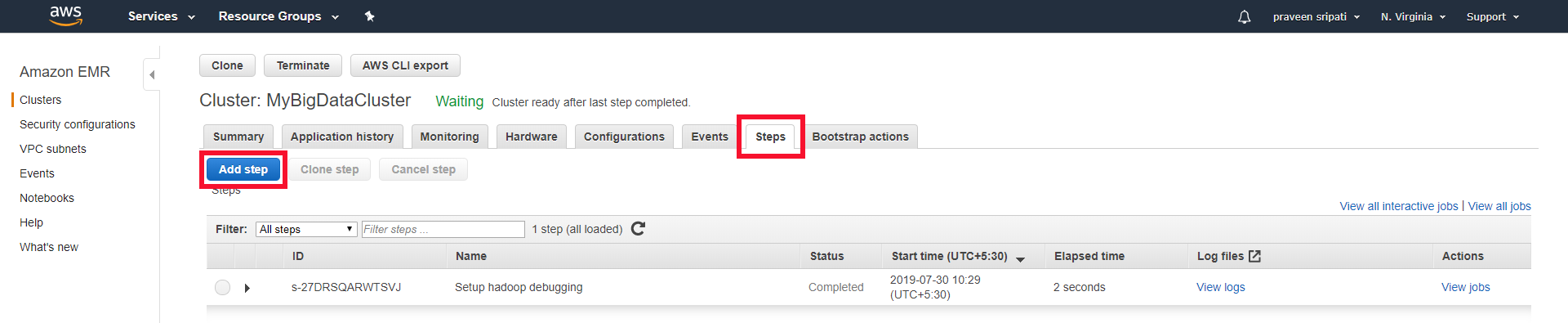
How To Create Hadoop Cluster With Amazon Emr Edureka

Apache Hadoop Cloud Data Architect

Hadoop Aws Marketplace
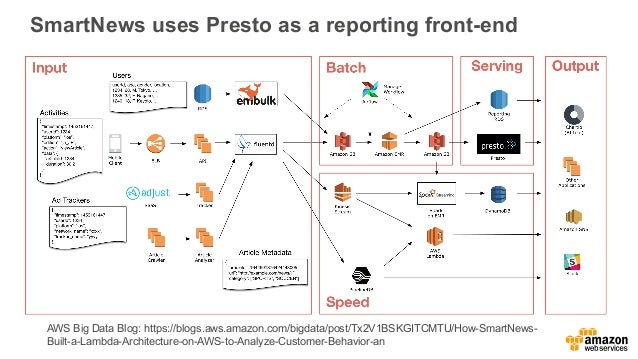
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop

Handle 0 Gb Of Data With Aws Ec2 Hadoop Cluster Filipyoo

Hdfs Vs S3 Aws S3 Vs Hadoop Hdfs Youtube

Tune Hadoop And Spark Performance With Dr Elephant And Sparklens On Amazon Emr Aws Big Data Blog

Aws Proserve Hadoop Cloud Migration For Property And Casualty Insurance Leader Softserve

Hadoop To Amazon Emr Migration I Lead A Team That Migrated A Hadoop By Tom Harrison Tom Harrison S Blog
Creating Ec2 Instances In Aws To Launch A Hadoop Cluster Hadoop In Real World
Q Tbn And9gcrpoiazujknxbkyzc B Hs 9uwoi3eggxmrf6edrhyl1pqmhvkq Usqp Cau

Advantages And Complexities Of Integrating Hadoop With Object Stores Cloud Computing News
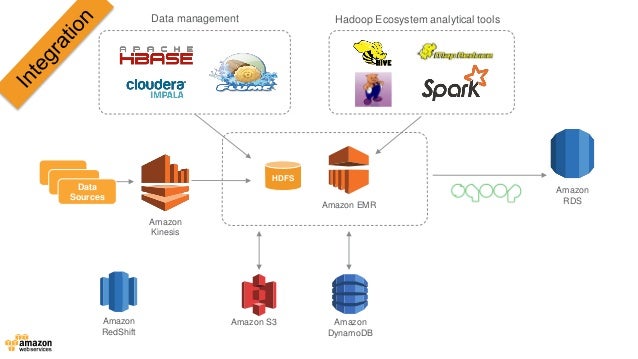
Big Data Use Cases And Solutions In The Aws Cloud

How To Setup An Apache Hadoop Cluster On Aws Ec2 Novixys Software Dev Blog

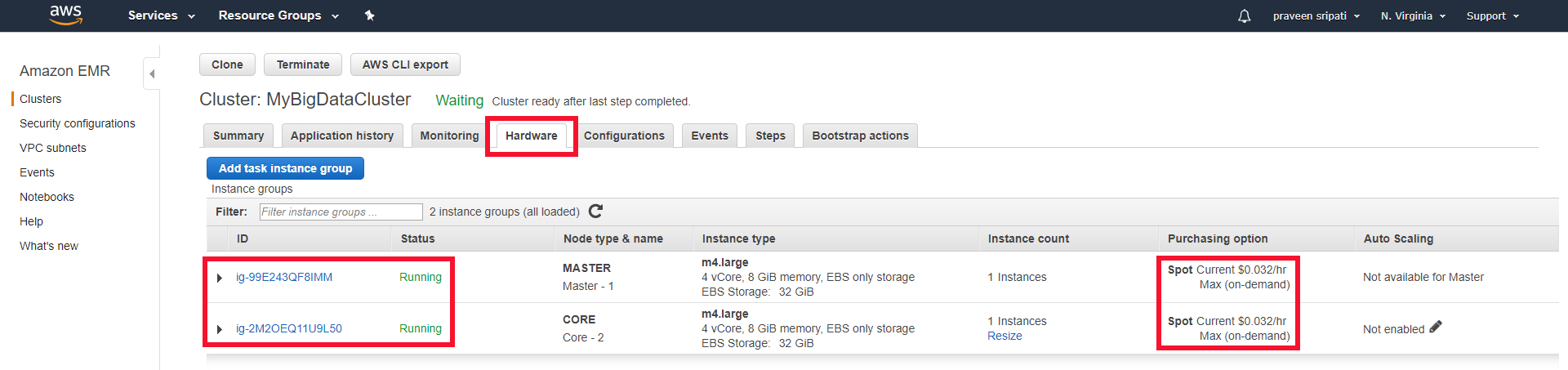
Lower Your Emr Costs By Leveraging Aws Spot Instances
How To Create Hadoop Cluster With Amazon Emr Edureka
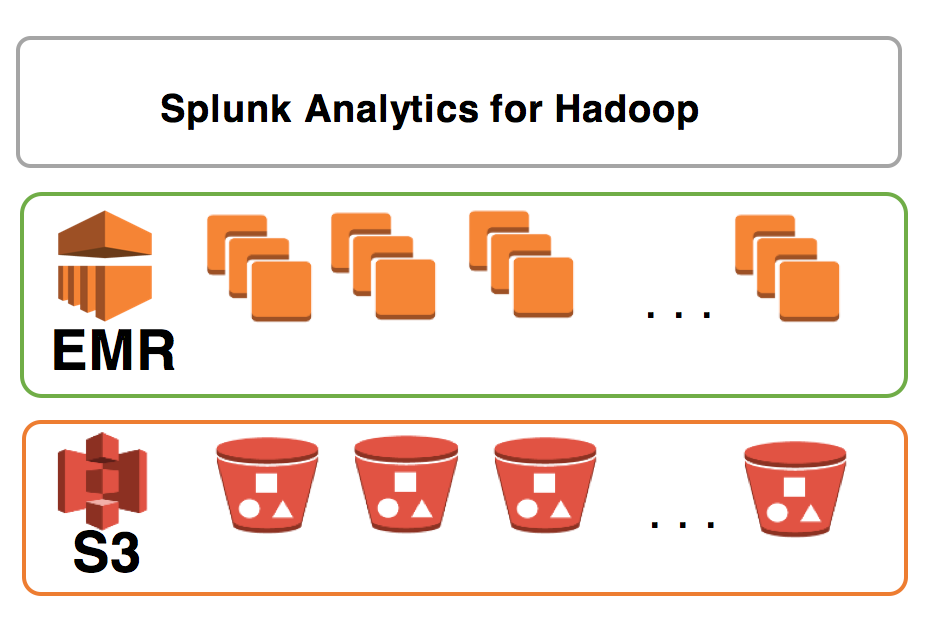
How To Splunk Analytics For Hadoop On Amazon Emr Splunk

Big Data Analytics Powered By Hadoop Faction Inc
Build A Hadoop Cluster In Aws In Minutes Dzone Cloud

Big Data On Cloud Hadoop And Spark On Emr Kaizen

Big Data Smart Labs Hadoop Deployment Lab For User Trial Poc On Aws Or Google Cloud Using Ravello Ravello Blog
1

Big Data On Amazon Elastic Mapreduce Step By Step Zdnet

How To Get Hadoop And Spark Up And Running On Aws By Hoa Nguyen Insight
Amazon Web Services Elastic Mapreduce Tutorialspoint
How To Install Apache Hadoop Cluster On Amazon Ec2 Tutorial Edureka
Learn The 10 Useful Difference Between Hadoop Vs Redshift
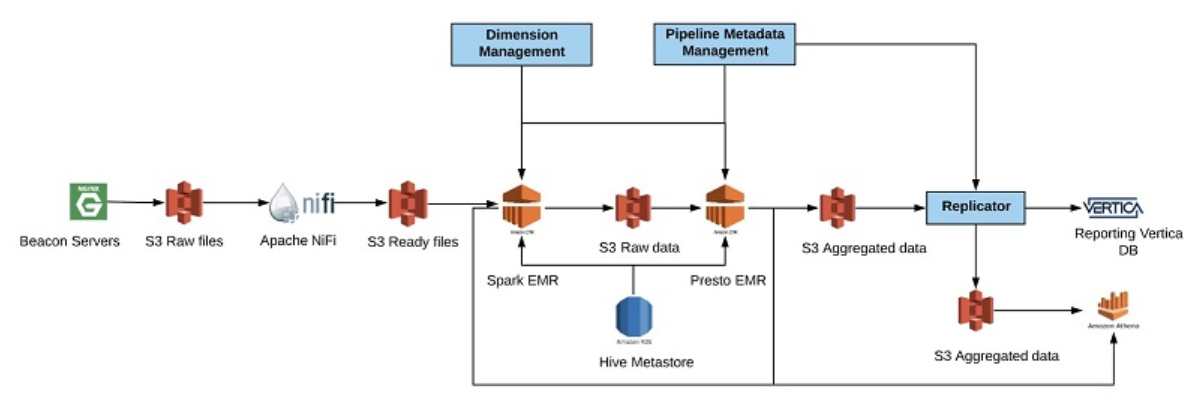
How Verizon Media Group Migrated From On Premises Apache Hadoop And Spark To Amazon Emr Aws Big Data Blog

Tips For Migrating To Apache Hbase On Amazon S3 From Hdfs Aws Big Data Blog
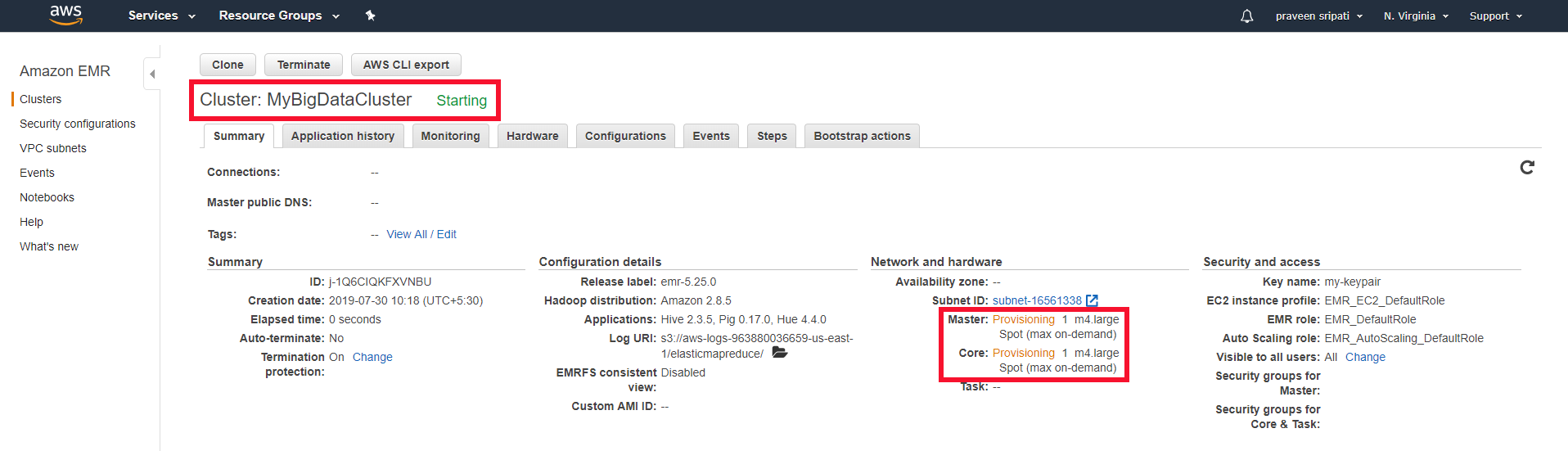
How To Create A Hadoop Cluster With Amazon Emr By Vishal Padghan Edureka Medium
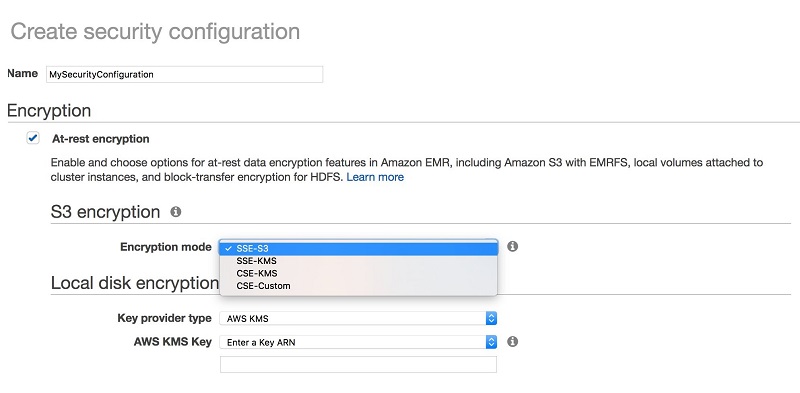
Best Practices For Securing Amazon Emr Aws Big Data Blog
Aws Instance To Setup Hadoop Cluster Ec2 Instances Setup Youtube

Using Aws Systems Manager Run Command To Submit Spark Hadoop Jobs On Amazon Emr Aws Management Governance Blog
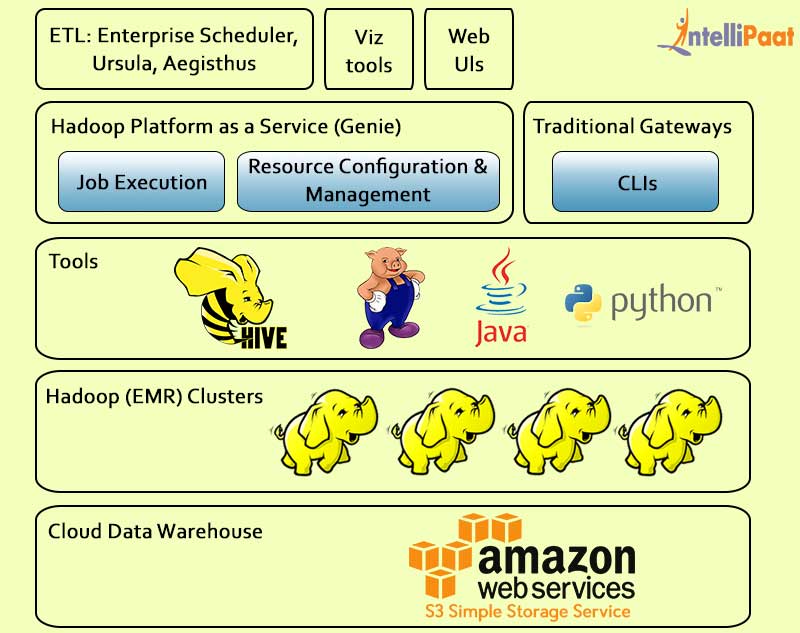
Top 6 Hadoop Vendors Providing Big Data Solutions Intellipaat Blog
Map Reduce With Python And Hadoop On Aws Emr By Chiefhustler Level Up Coding
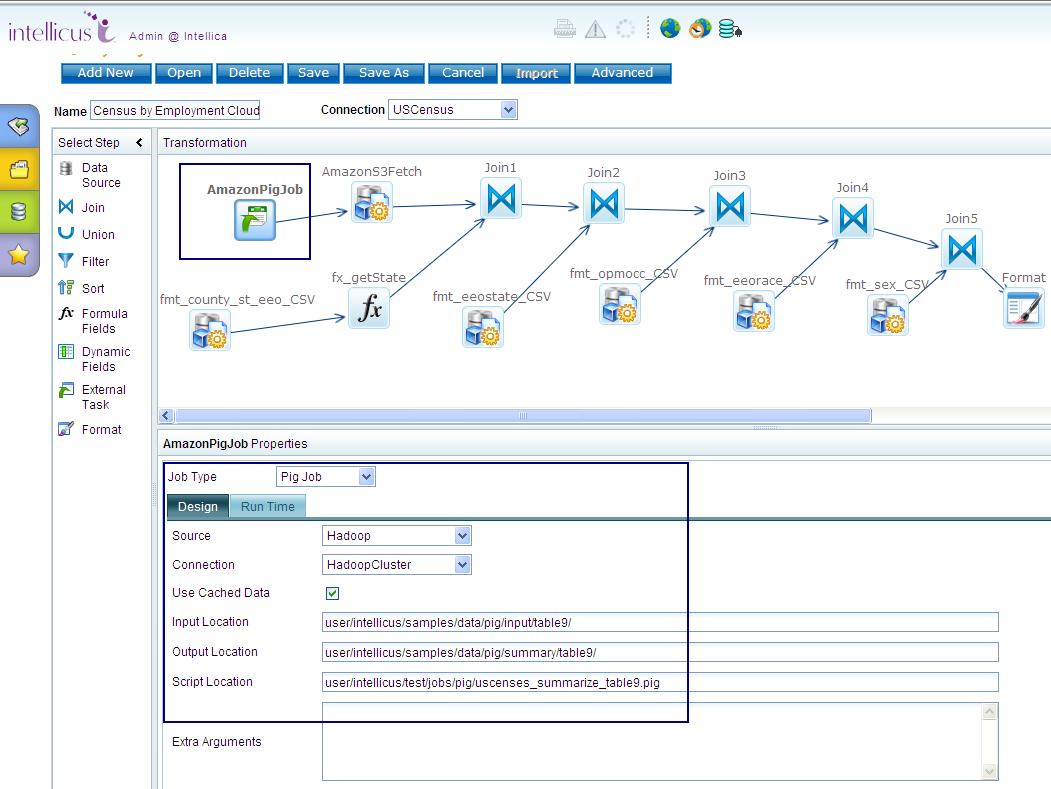
Intellicus 6 0 Release Notes Big Data Enhancements

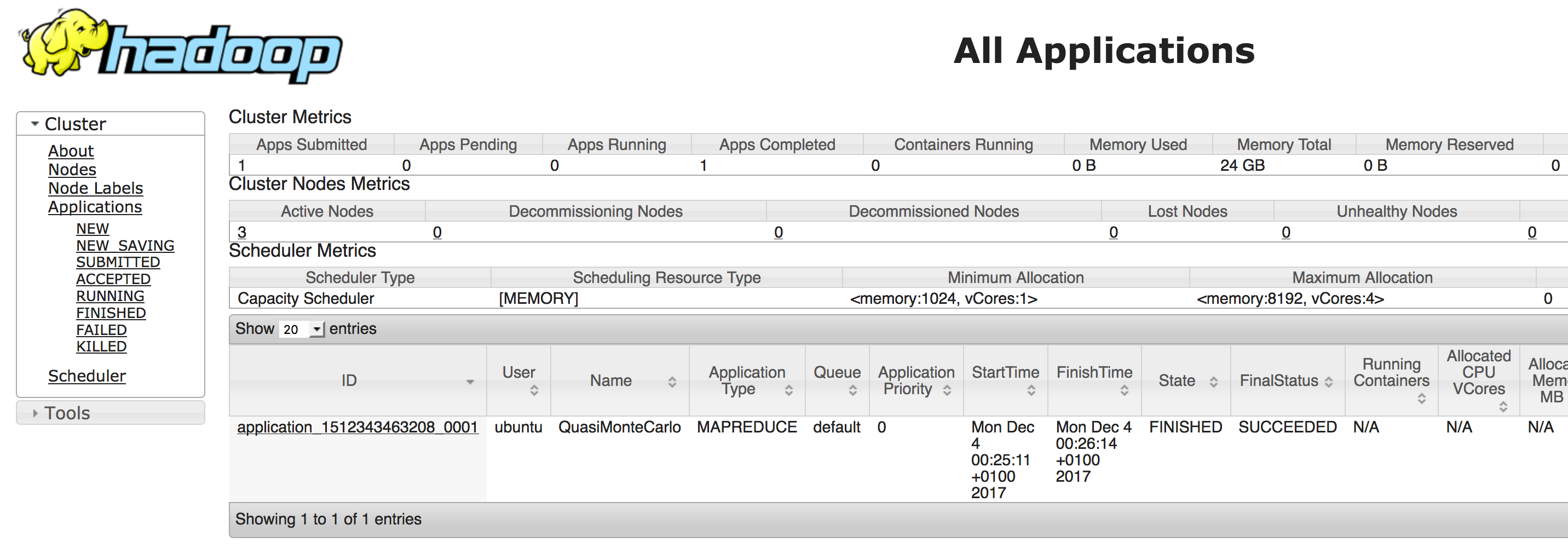
Hadoop Tutorial 3 1 Using Amazon S Wordcount Program Dftwiki
Build A Hadoop Cluster In Aws In Minutes Dzone Cloud
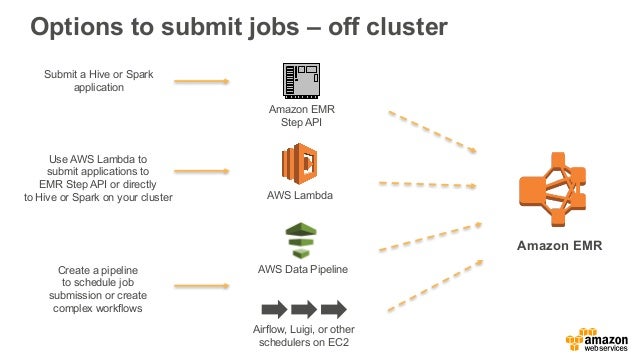
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop
A Step By Step Guide To Install Hadoop Cluster On Amazon Ec2 Eduonix Blog
Let S Try Hadoop On Aws A Simple Hadoop Cluster With 4 Nodes A By Gael Foppolo Gael Foppolo
Why Hadoop Data Lakes Are Not The Modern Architect S Choice Bryteflow
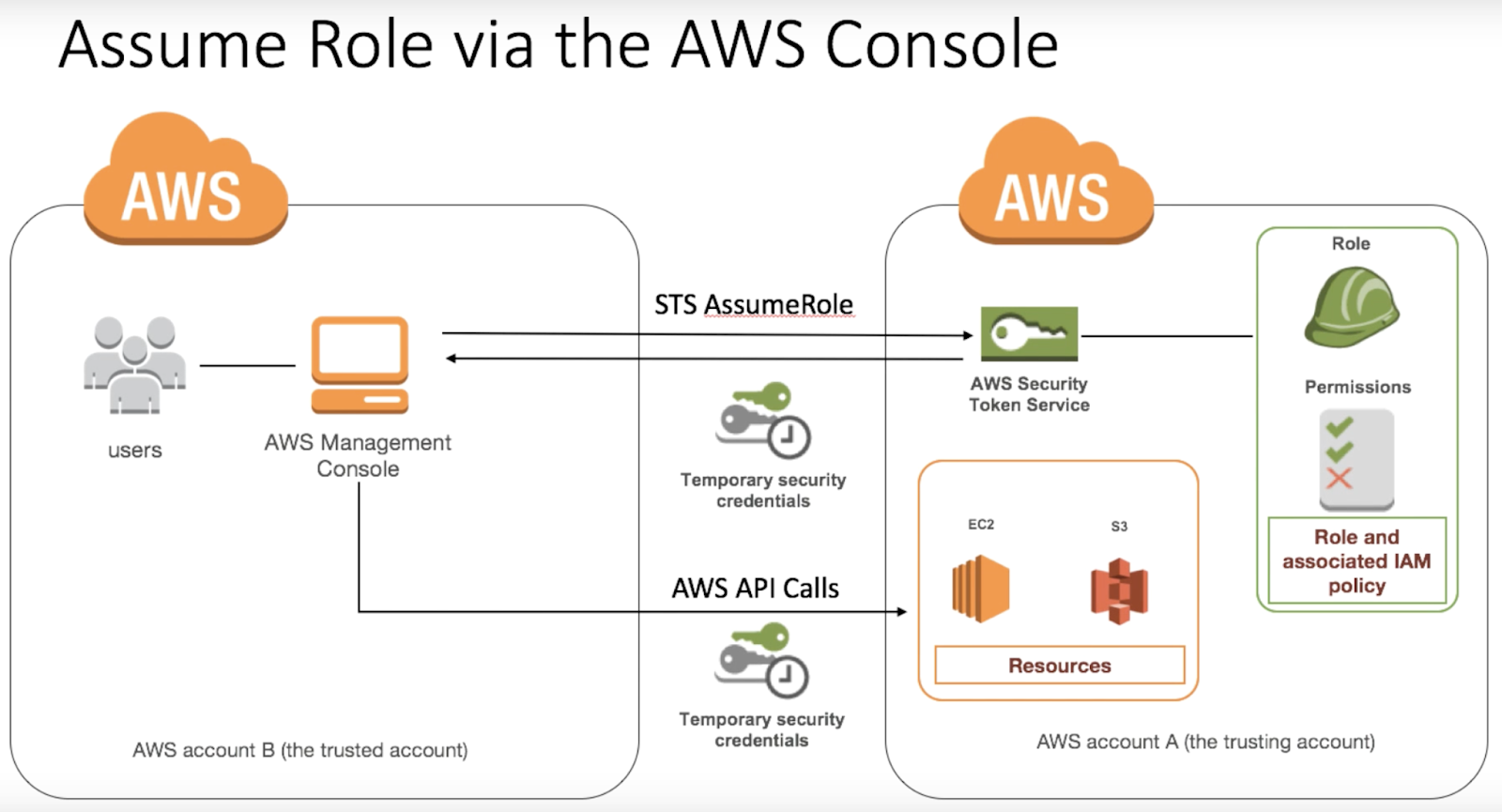
Aws Azure Cloud Spark Hadoop Linux Assume Role To Write In Cross Account S3 Bucket
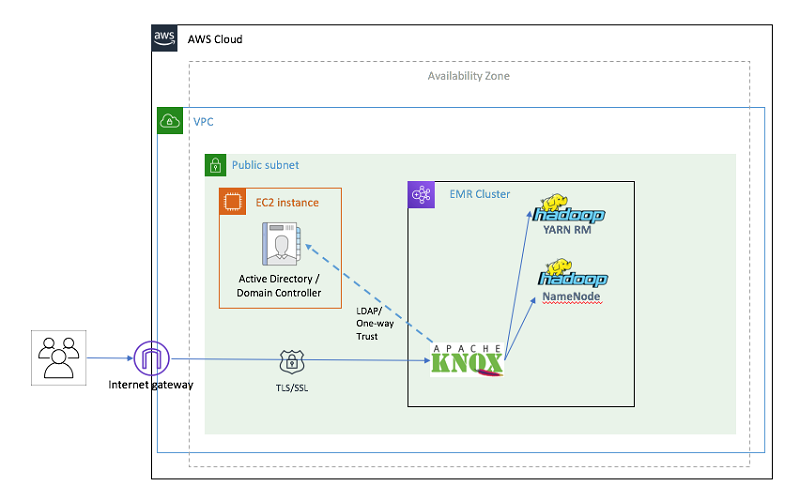
Implement Perimeter Security In Amazon Emr Using Apache Knox Aws Big Data Blog
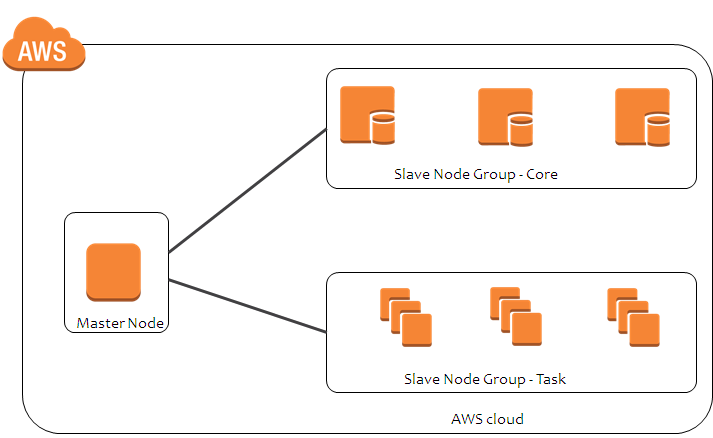
Amazon Emr Five Ways To Improve The Way You Use Hadoop

4 3 Hadoop On Amazon Elastic Map Reduce Emr Cbtuniversity

How To Setup An Apache Hadoop Cluster On Aws Ec2 Novixys Software Dev Blog
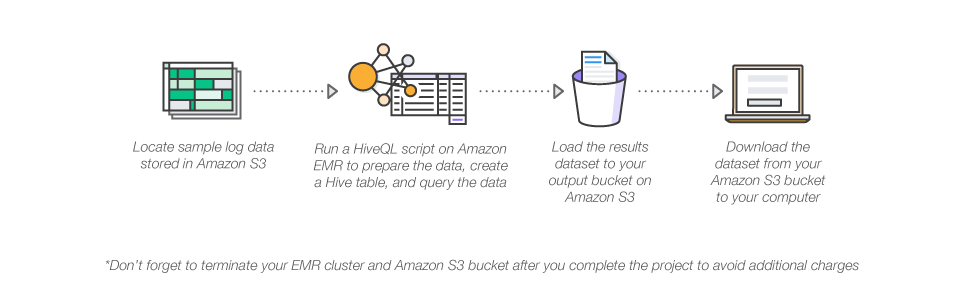
How To Analyze Big Data With Hadoop Amazon Web Services Aws

Building For The Internet Of Things With Hadoop
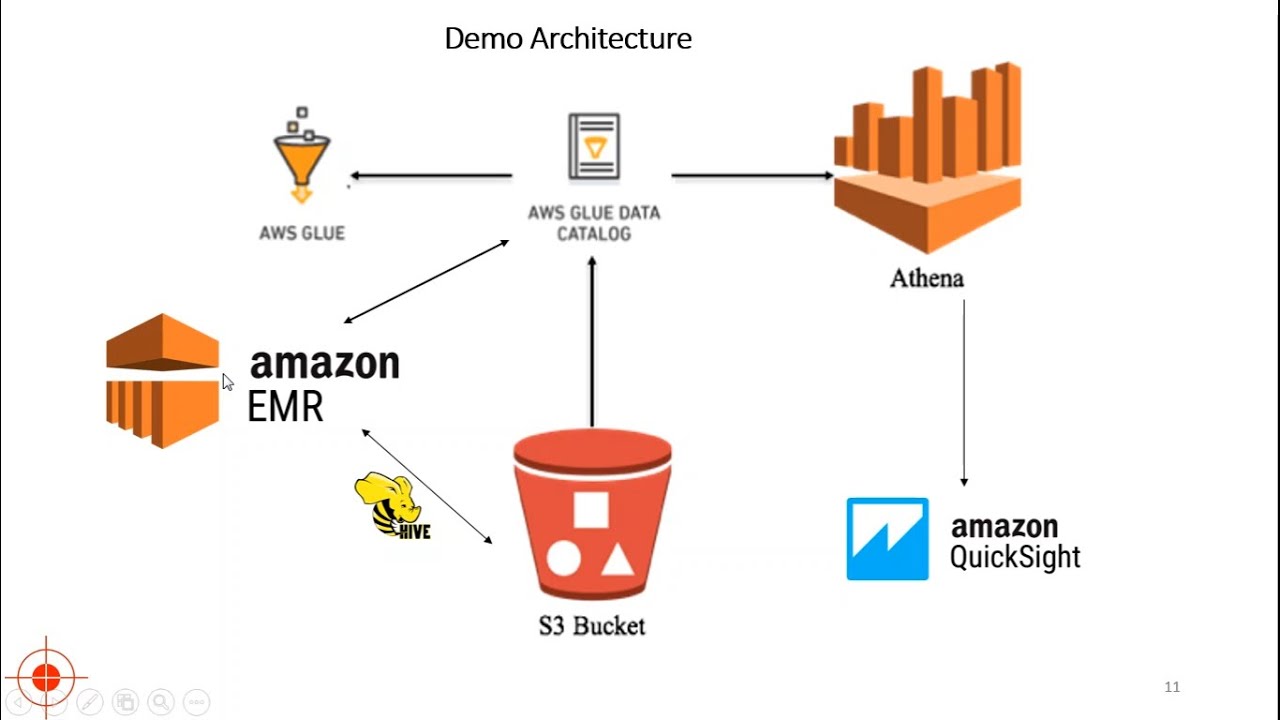
Hadoop On Aws Using Emr Tutorial S3 Athena Glue Quicksight Youtube

Netflix Open Sources Its Hadoop Manager For Aws Open Source Netflix Data Analysis Tools

A Hadoop Ecosystem On Aws Hands On Devops Book

Cost Analysis Of Building Hadoop Clusters Using Cloud Technologies Qubole
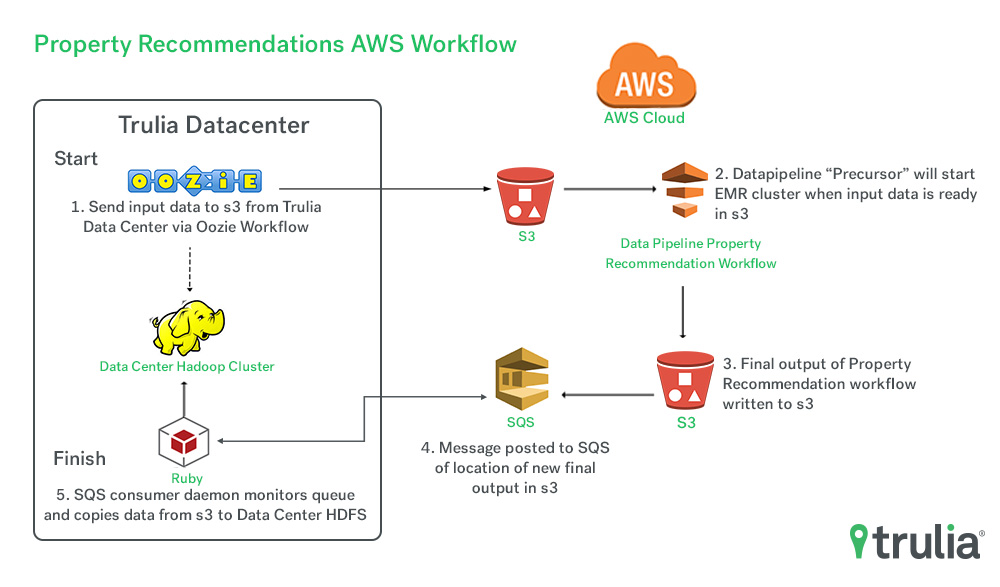
Optimizing Our Workflow With Aws Trulia S Blog

Set Up Hadoop Multi Nodes Cluster On Aws Ec2 A Working Example Using Python With Hadoop Streaming Filipyoo

Amazon Emr Vs Hadoop What Are The Differences
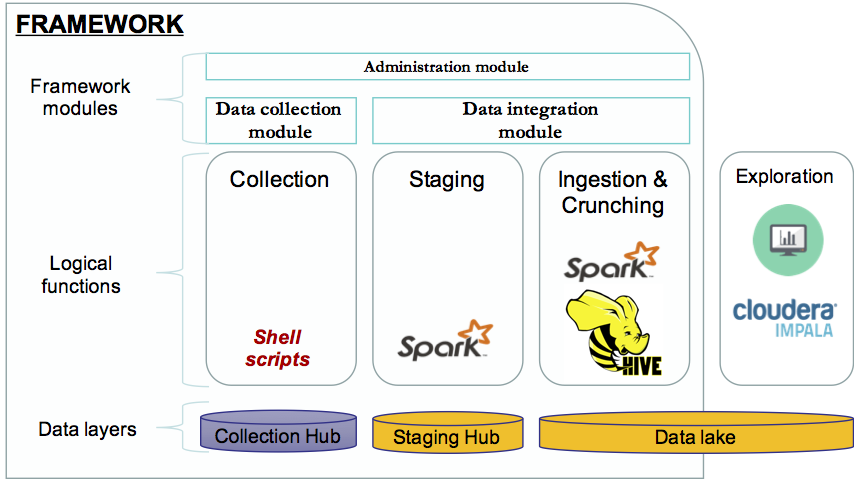
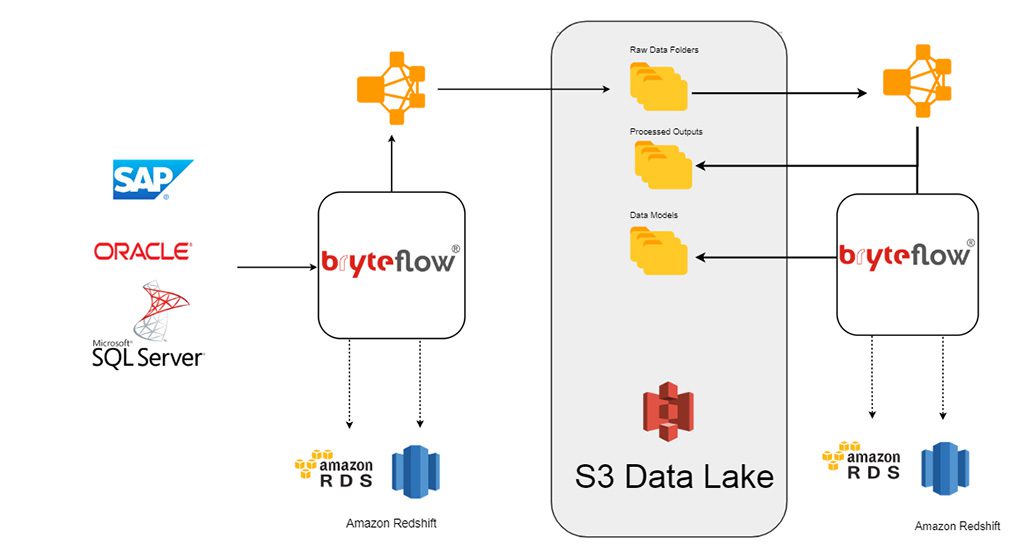
Hadoop Data Integration How To Streamline Your Etl Processes With Apache Spark
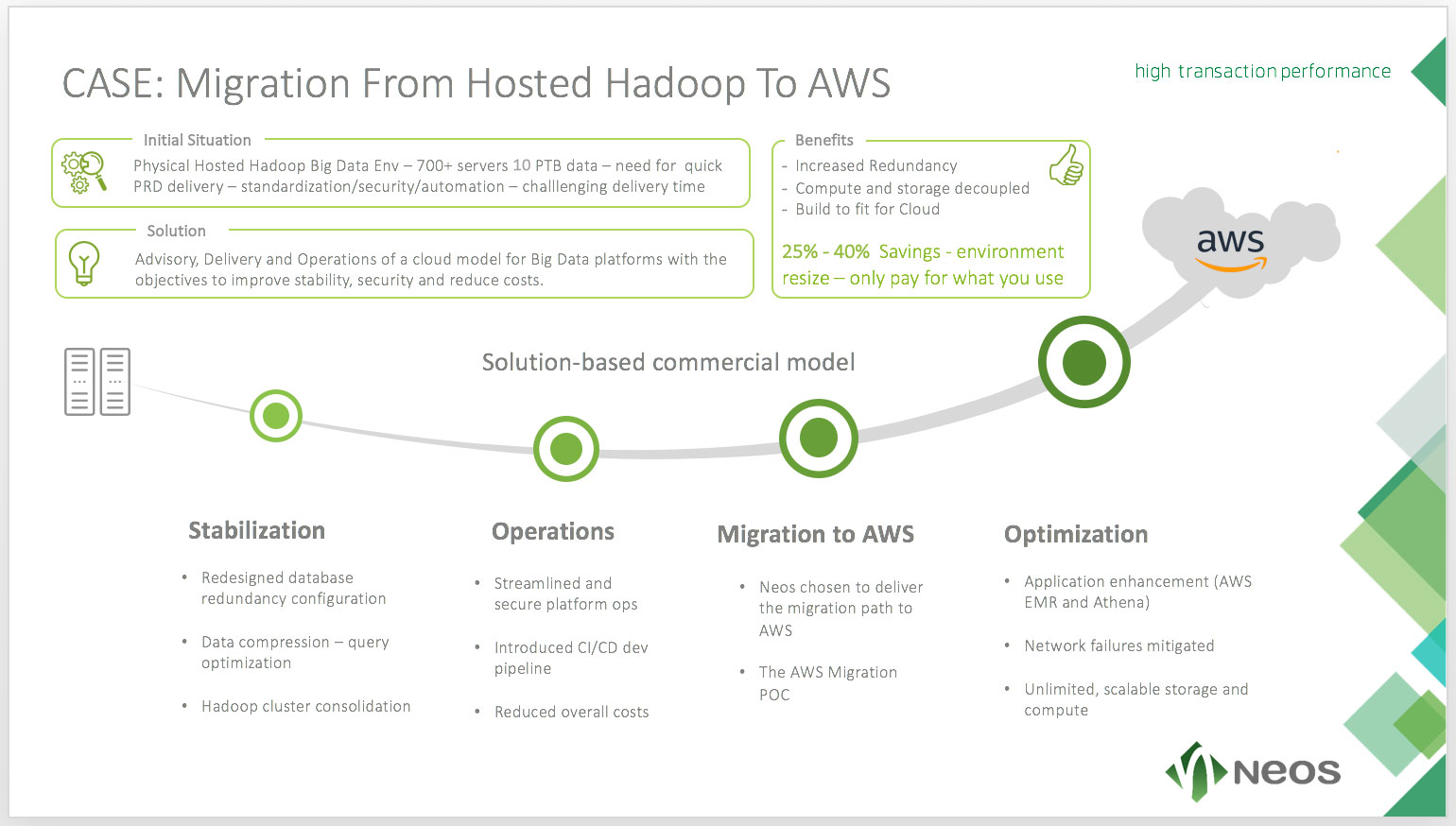
Neos It Services Project Reference Hosted Hadoop To Public Cloud
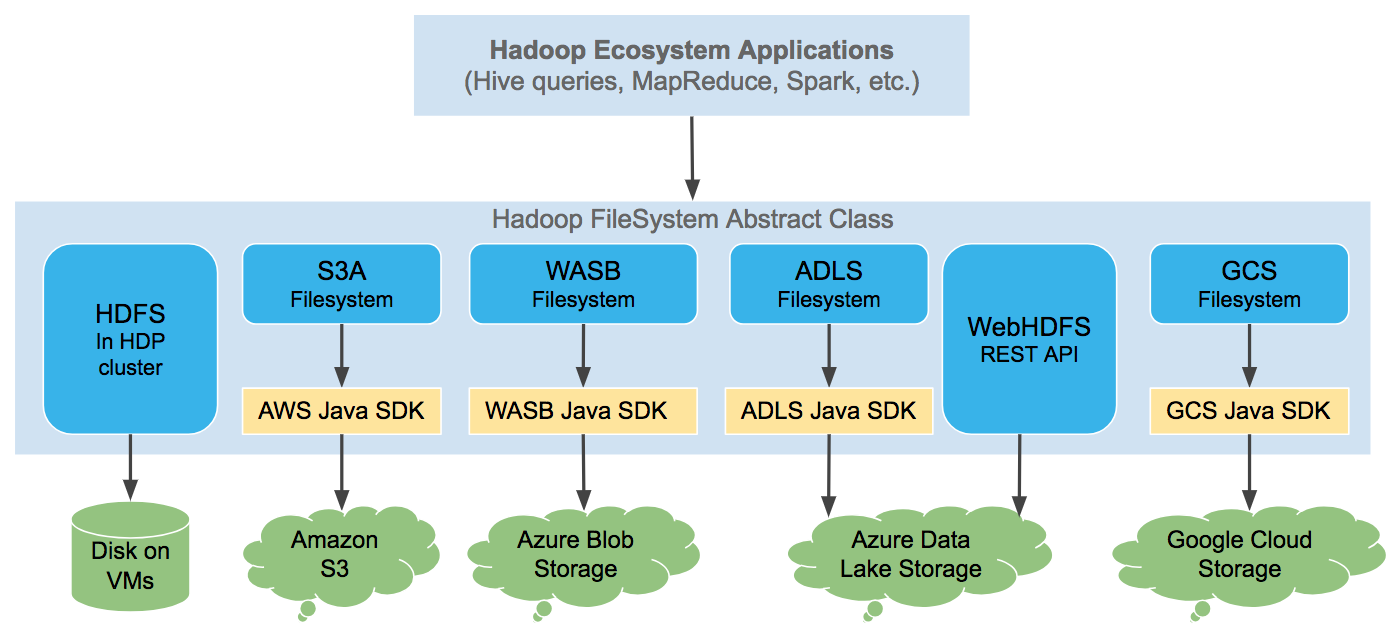
Chapter 2 The Cloud Storage Connectors Hortonworks Data Platform
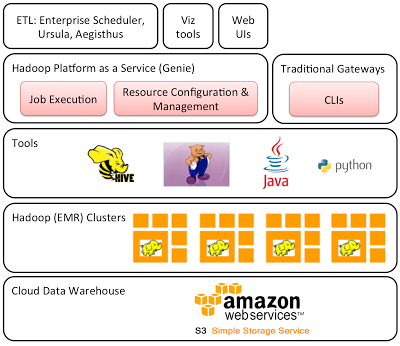
Hadoop Platform As A Service In The Cloud By Netflix Technology Blog Netflix Techblog
Q Tbn And9gctag4mznb T1wwko 4xj5b8riqjakobr8f 8b3ohbnncmc2s8xn Usqp Cau

Aws Emr Spark On Hadoop Scala Anshuman Guha

Creating A Kerberized Emr Cluster For Use With Ae 5 Anaconda Platform 5 2 0 Documentation
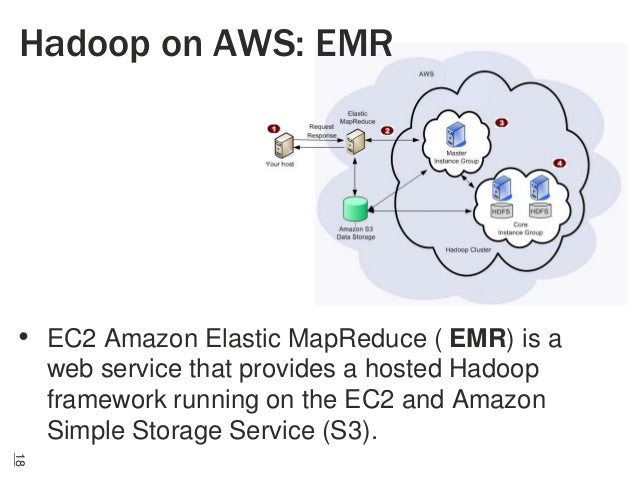
Hadoop Aws Infrastructure Cost Evaluation
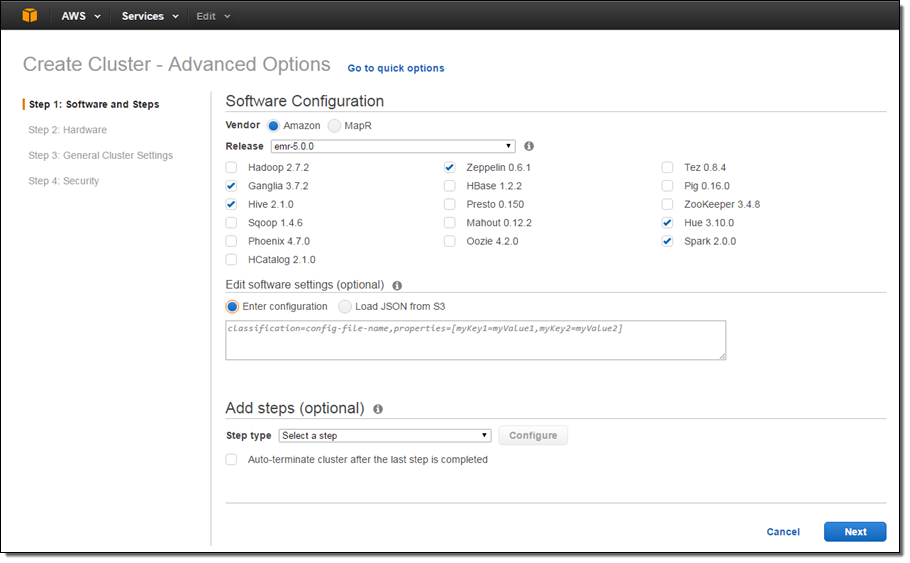
Amazon Emr 5 0 0 Major App Updates Ui Improvements Better Debugging And More Aws News Blog

Amazon Web Services Releases Version 5 0 0 Of Elastic Mapreduce Which Updates Eight Hadoop Projects Geekwire
Hadoop Workloads On Aws Azure Gce And Oci Download Scientific Diagram
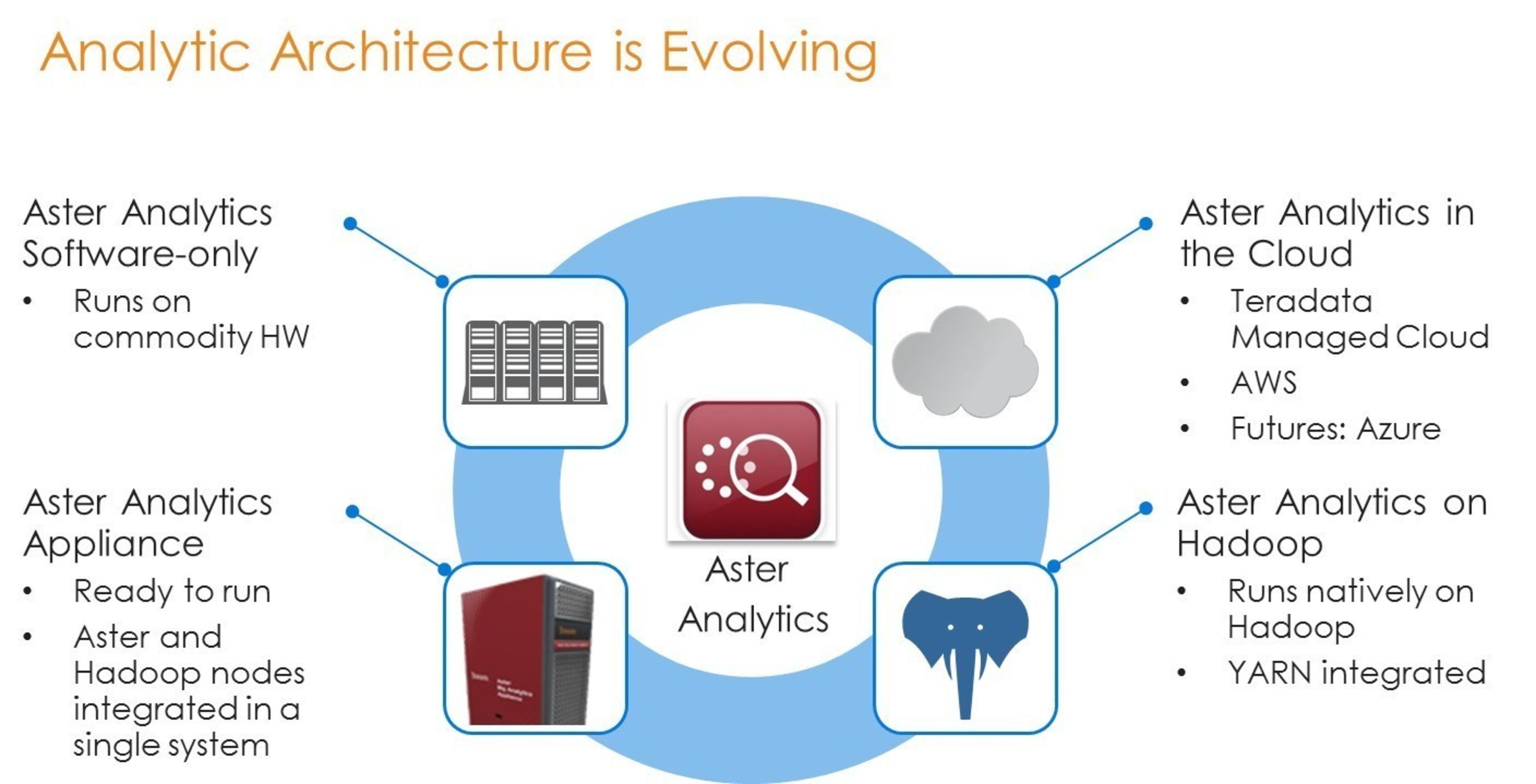
Teradata Aster Analytics Going Places On Hadoop And Aws

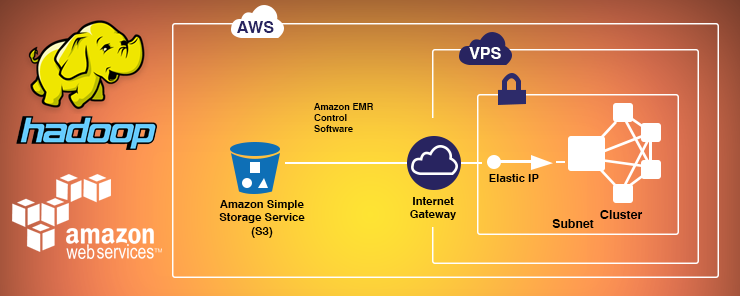
Launching And Running An Amazon Emr Cluster Inside A Vpc Aws Big Data Blog
Q Tbn And9gcsyjxdjvgbdh97xfv1ibyv5ns6mue4vuslxor9txjjzmafwtwun Usqp Cau

Project Management Technology Fusion Apache Hadoop Spark Kafka Versus Aws Emr Spark Kinesis Stream
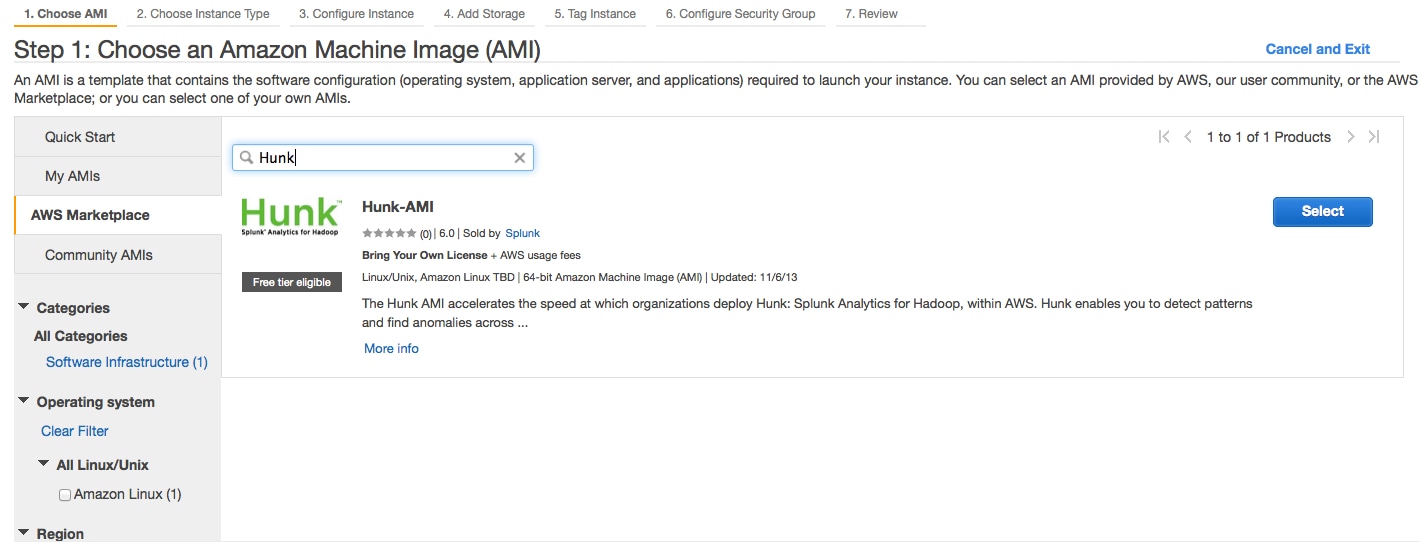
Analyze Data With Hunk On Amazon Emr Splunk

Top 6 Hadoop Vendors Providing Big Data Solutions In Open Data Platform

Filipyoo

Map Reduce With Python And Hadoop On Aws Emr By Chiefhustler Level Up Coding
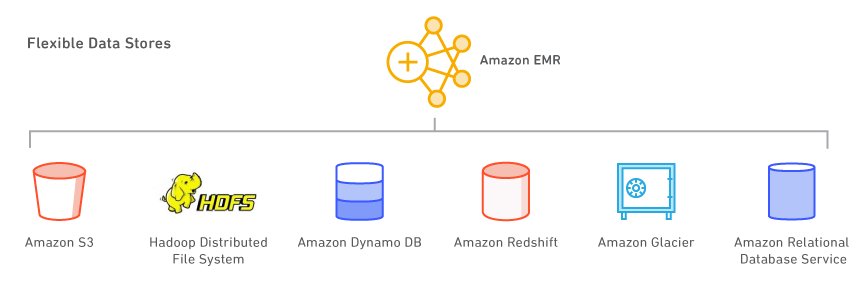
Amazon Emr Features Big Data Platform Amazon Web Services

What Is Hadoop

Installing An Aws Emr Cluster Tutorial Big Data Demystified

Administration Streamanalytix



