Aws Hadoop Architecture
This is all how “real” Hadoop tokens work The S3A Delegation Tokens are subtly different The S3A DTs actually include the AWS credentials within the token data marshalled and shared across the cluster The credentials can be one of The Full AWS (fss3aaccesskey, fss3asecretkey) login.

Aws hadoop architecture. Find the variable, HADOOP_VER, and change it to your desired version number;. Hadoop is suitable for Massive Offline batch processing, by nature cannot be and should not be used for online analytic Unlikely, Amazon Redshift is built for Online analytical purposes * Massively parallel processing * Columnar data storage. Hortonworks Data Platform based architecture In order to meet deadlines associated with expiration of a Hortonworks support contract, the decision was made to go with Primary Scenario SoftServe customized a default Amazon EMR setup, integrated native and third party components with security and audit, designed the data transfer process from the onprem data platform to the AWSbased platform.
Locate the HADOOP_URL variable and point it to where you want to pull the desired version’s binary Of course you must make sure the binary exists — either move it to your own personal S3 bucket and reference that location — or point it the Apache site knowing. Setup & config instances on AWS;. But AWS is a pioneer in this area and lot of successful websites like netflix, reddit, yelp etc are powered by AWS Installation Type & High Level Architechture There are few different ways to install a Hadoop cluster.
6Hadoop is a File System architecture based on Java Application Programming Interfaces (API) whereas Redshift is based on Relational model Database Management System (RDBMS) 7Hadoop can have integrations with different vendors and Redshift has no support in this case where Amazon is their only vendor. We will try to create an image from an existing AWS EC2 instance after installing java and hadoop on it If there is no instance created yet, create one and login to the instance using this article. Apache Hadoop is an open source framework that is used to efficiently store and process large datasets ranging in size from gigabytes to petabytes of data Instead of using one large computer to store and process the data, Hadoop allows clustering multiple computers to analyze massive datasets in parallel more quickly.
AWS Redshift is a cloud data warehouse that uses an MPP architecture (very similar to Hadoop’s distributed file system we recommend reading our guide) and columnar storage, making analytical queries very fast Moreover, it is SQL based, which makes it easy to adopt by data analysts. Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath. Data Warehousing with Apache Hive on AWS Architecture Patterns This article focuses on the business value of a big data warehouse using Apache Hive, and provides pointers to architecture, design and implementation best practices needed to implement such a system Hive and Hadoop are optimized for writeonce and readmany patterns Any.
AWS EC2 Tutorial Steps for Instance Creation Next in this AWS EC2 Tutorial, let’s understand the whole EC2 instance creation process through a use case in which we’ll be creating an Ubuntu instance for a test environment Login to AWS Management Console Select your preferred Region. Lack of agility, excessive costs, and administrative overhead are convincing onpremises Spark and Hadoop customers to migrate to cloud native services on AWS Whether you're using Cloudera, Hortonworks, MapR, Unravel helps ensure you won’t be flying blind moving workloads to the cloud. ️ Setup AWS instance We are going to create an EC2 instance using the latest Ubuntu Server as OS After logging on AWS, go to AWS Console, choose the EC2 service On the EC2 Dashboard, click on Launch Instance.
Each of the layers in the Lambda architecture can be built using various analytics, streaming, and storage services available on the AWS platform Figure 2 Lambda Architecture Building Blocks on AWS The batch layer consists of the landing Amazon S3 bucket for storing all of the data (eg,. One of the really great things about Amazon Web Services (AWS) is that AWS makes it easy to create structures in the cloud that would be extremely tedious and timeconsuming to create onpremises For example, with Amazon Elastic MapReduce (Amazon EMR) you can build a Hadoop cluster within AWS without the expense and hassle of provisioning. Apache Hive, initially developed by Facebook, is a popular big data warehouse solution It provides a SQL interface to query data stored in Hadoop distributed file system (HDFS) or Amazon S3 (an AWS implementation) through an HDFSlike abstraction layer called EMRFS (Elastic MapReduce File System) Apache Hive on EMR Clusters.
HDFS is the canonical file system for Hadoop, but Hadoop’s file system abstraction supports a number of alternative file systems, including the local file system, FTP, AWS S3, Azure’s file system, and OpenStack’s Swift. Hadoop MapReduce is an opensource programming model for distributed computing It simplifies the process of writing parallel distributed applications by handling all of the logic, while you provide the Map and Reduce functions The Map function maps data to sets of keyvalue pairs called intermediate results. Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure that HADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath.
Hadoop Architecture Apache Hadoop was developed with the goal of having an inexpensive, redundant data store that would enable organizations to leverage Big Data Analytics economically and increase the profitability of the business A Hadoop architectural design needs to have several design factors in terms of networking, computing power, and storage. It will pull in a compatible awssdk JAR The hadoopaws JAR does not declare any dependencies other than. An IAM instance role with finegrained permissions for access to AWS services necessary for the deployment process In this reference architecture, we support two options for deploying Cloudera's Enterprise Data Hub within a VPC builds the EDH cluster by launching all the Hadooprelated EC2 instances within the public subnet In this.
As opposed to AWS EMR, which is a cloud platform, Hadoop is a data storage and analytics program developed by Apache You can think of it this way if AWS EMR is an entire car, then Hadoop is akin to the engine. Amazon’s EMR is a managed Hadoop cluster that can process a large amount of data at low cost A typical data processing involves setting up a Hadoop cluster on EC2, set up data and processing. Getting Started S3A depends upon two JARs, alongside hadoopcommon and its dependencies hadoopaws JAR;.
AWS ProServe Hadoop Cloud Migration for Property and Casualty Insurance Leader Our client is a leader in property and casualty insurance, group benefits and mutual funds With more than 0 years of expertise, the company is widely recognized for its service excellence, sustainability practices, trust and integrity. A key part of the Workshop is discussing your current onpremises Apache Hadoop/Spark architecture, your workloads, and your desired future architecture Complete the form and one of our technical experts will contact you to confirm the best date and time for your team to attend the online workshop. Enterprise Reference Architecture for Apache Hadoop – AWS Cloud Many Fortune 500 organizations are adopting AWS to deploy Java applications services , however, Cloudera Enterprise makes it possible for organizations to deploy the Hadoop clusters in the AWS cloud.
Setup & config a Hadoop cluster on these instances;. In this video we will compare HDFS vs AWS S3, and compare and contrast scenarios where S3 is better than HDFS and scenarios where HDFS is better than Amazon. Try our Hadoop cluster;.
What you'll accomplish Launch a fully functional Hadoop cluster using Amazon EMR Define the schema and create a table for sample log data stored in Amazon S3 Analyze the data using a HiveQL script & write the results back to Amazon S3 Download and view the results on your computer. Lastly, because AWS EMR is a software as a service (SaaS) and it’s backed by Amazon, it allows professionals to access support quickly and efficiently Hadoop 101 As opposed to AWS EMR, which is a cloud platform, Hadoop is a data storage and analytics program developed by Apache. In this video we will compare HDFS vs AWS S3, and compare and contrast scenarios where S3 is better than HDFS and scenarios where HDFS is better than Amazon.
Hadoop Basics • Introduction to Hadoop • Hadoop core components • HDFS Hadoop Storage Layer • MapReduce – Hadoop Processing Layer • YARN – Hadoop 2, x Hadoop Ecosystem Tools overview • Pig • Hive • Impala • HBase • Sqoop • Oozie Hive • Introduction to Apache Hive • Architecture of Hive • Hive megastore and. The AWS Glue service is an Apache compatible Hive serverless metastore which allows you to easily share table metadata across AWS services, applications, or AWS accounts This provides several concrete benefits Simplifies manageability by using the same AWS Glue catalog across multiple Databricks workspaces. This is all how “real” Hadoop tokens work The S3A Delegation Tokens are subtly different The S3A DTs actually include the AWS credentials within the token data marshalled and shared across the cluster The credentials can be one of The Full AWS (fss3aaccesskey, fss3asecretkey) login.
AWS Redshift is a cloud data warehouse that uses an MPP architecture (very similar to Hadoop’s distributed file system we recommend reading our guide) and columnar storage, making analytical queries very fast Moreover, it is SQL based, which makes it easy to adopt by data analysts. Apache Hadoop was developed with the goal of having an inexpensive, redundant data store that would enable organizations to leverage Big Data Analytics economically and increase the profitability of the business A Hadoop architectural design needs to have several design factors in terms of networking, computing power, and storage. HDFS Topology – Apache Hadoop HDFS Architecture – awsseniorcom Apache HDFS or Hadoop Distributed File System is a blockstructured file system where each file is divided into blocks of a predetermined size These blocks are stored across a cluster of one or several machines Apache Hadoop HDFS Architecture follows a Master/Slave.
This article is the 2nd part of a serie of several posts where I describe how to build a 3node Hadoop cluster on AWS • Part 1 Setup EC2 instances with AWS CloudFormation Following our previous. Course will also touch upon the best practices followed on AWS architecture principles Who this course is for Beginnner and practicing AWS and onpremise Hadoop architects Who have prior informaiton on the Big data and AWS platforms This course is still under construction So please go ahead and watch it as in when new content get uploaded. AWS ProServe Hadoop Cloud Migration for Property and Casualty Insurance Leader Our client is a leader in property and casualty insurance, group benefits and mutual funds With more than 0 years of expertise, the company is widely recognized for its service excellence, sustainability practices, trust and integrity.
Hadoop is used mainly for diskheavy operations with the MapReduce paradigm, and Spark is a more flexible, but more costly inmemory processing architecture Both are Apache toplevel projects, are often used together, and have similarities, but it’s important to understand the features of each when deciding to implement them. The versions of hadoopcommon and hadoopaws must be identical To import the libraries into a Maven build, add hadoopaws JAR to the build dependencies;. HDFS architecture The Hadoop Distributed File System (HDFS) is the underlying file system of a Hadoop cluster It provides scalable, faulttolerant, rackaware data storage designed to be deployed on commodity hardware Several attributes set HDFS apart from other distributed file systems.
Hadoop is suitable for Massive Offline batch processing, by nature cannot be and should not be used for online analytic Unlikely, Amazon Redshift is built for Online analytical purposes * Massively parallel processing * Columnar data storage. The AWS Glue service is an Apache compatible Hive serverless metastore which allows you to easily share table metadata across AWS services, applications, or AWS accounts This provides several concrete benefits Simplifies manageability by using the same AWS Glue catalog across multiple Databricks workspaces. Source Screengrab from "Building Data Lake on AWS", Amazon Web Services, Youtube The primary benefit of processing with EMR rather than Hadoop on EC2 is the cost savings.
The holistic view of Hadoop architecture gives prominence to Hadoop common, Hadoop YARN, Hadoop Distributed File Systems (HDFS) and Hadoop MapReduce of the Hadoop Ecosystem Hadoop common provides all Java libraries, utilities, OS level abstraction, necessary Java files and script to run Hadoop, while Hadoop YARN is a framework for job. 1 HDFS HDFS stands for Hadoop Distributed File System It provides for data storage of Hadoop HDFS splits the data unit into smaller units called blocks and stores them in a distributed manner.
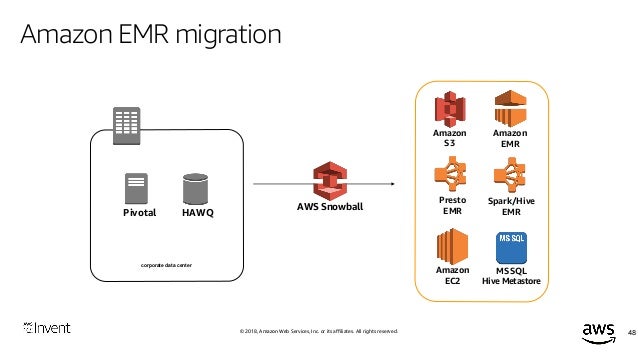
Migrate Your Hadoop Spark Workload To Amazon Emr And Architect It For
Docs Cloudera Com Documentation Other Reference Architecture Pdf Cloudera Ref Arch Aws Pdf

Amazon Emr Tutorials Dojo
Aws Hadoop Architecture のギャラリー
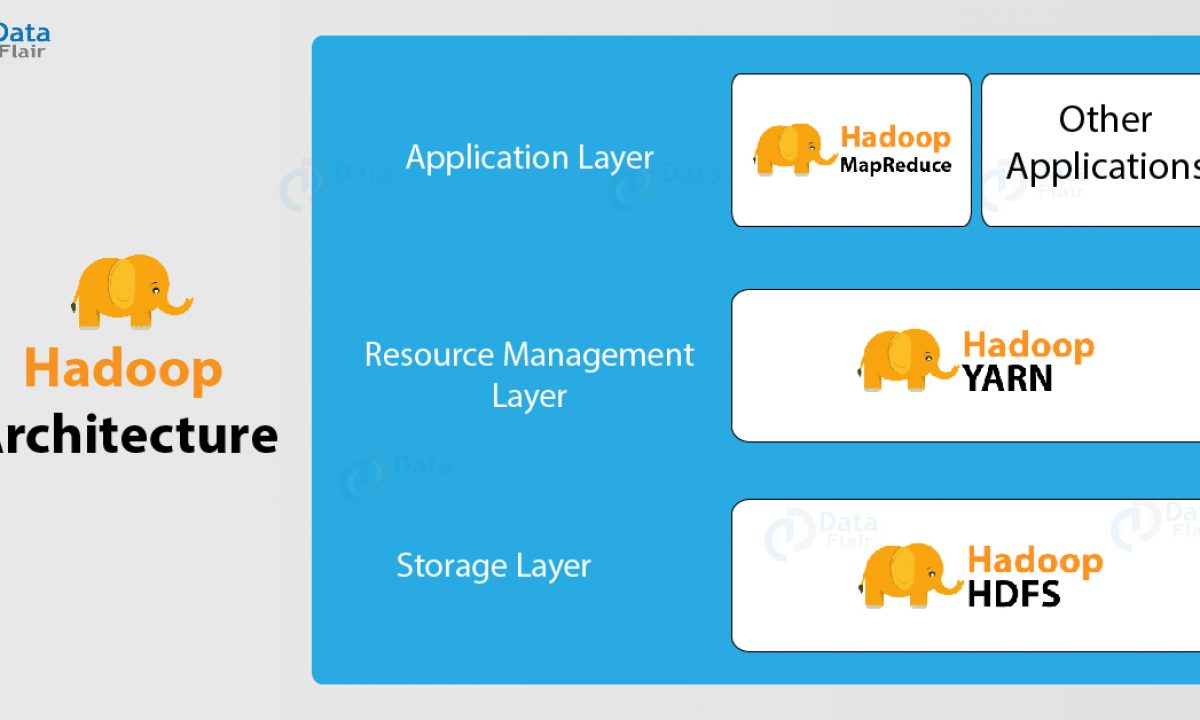
Hadoop Architecture In Detail Hdfs Yarn Mapreduce Dataflair
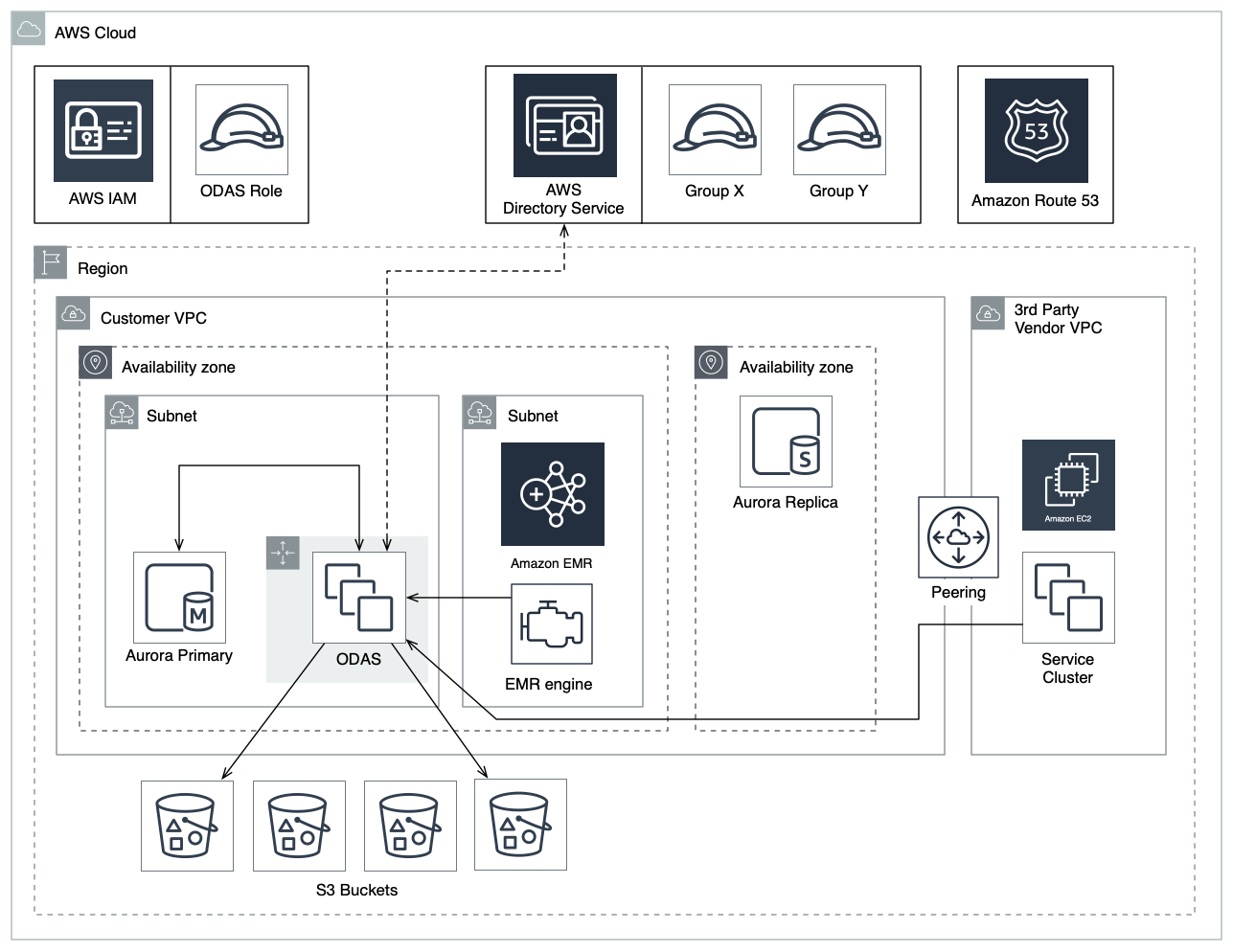
Aws Overview Okera Documentation

Aws Proserve Hadoop Cloud Migration For Property And Casualty Insurance Leader Softserve

Hadoop Vs Spark A Head To Head Comparison Logz Io
Www Netapp Com Media Tr 4529 Pdf

Apache Hadoop Architecture Explained In Depth Overview
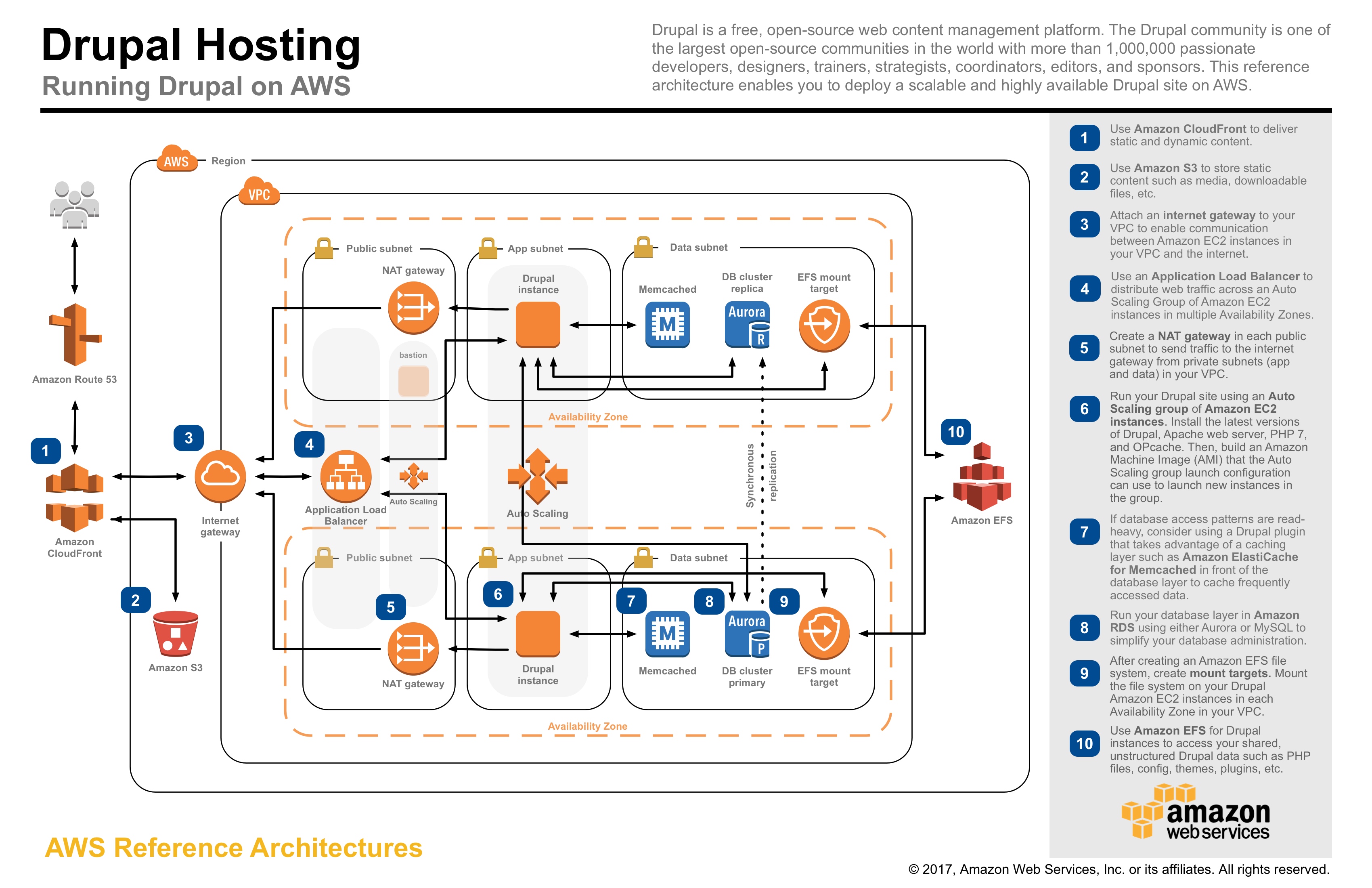
Aws Application Architecture Center
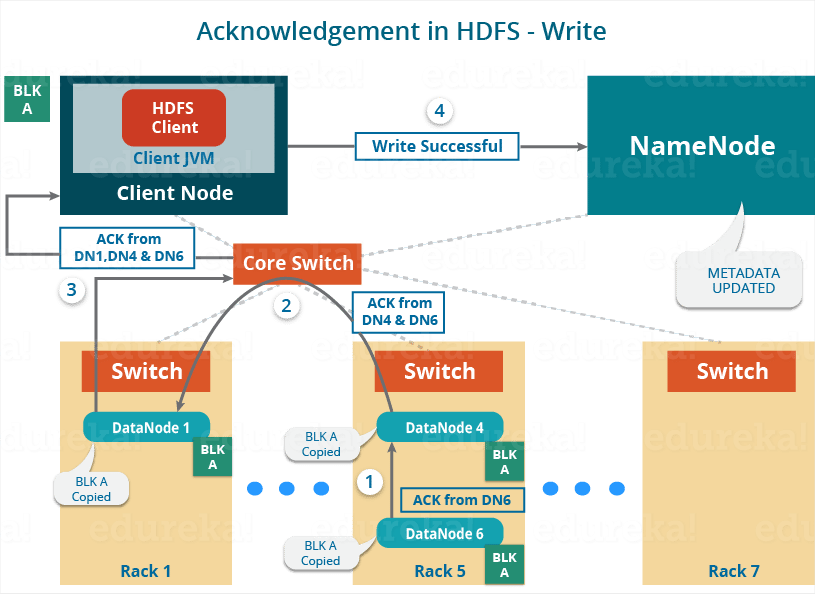
Hadoop Distributed File System Apache Hadoop Hdfs Architecture Edureka
Aws Quickstart S3 Amazonaws Com Quickstart Datalake Cognizant Talend Doc Data Lake On The Aws Cloud With Talend Big Data Platform Pdf

Aws Proserve Hadoop Cloud Migration For Property And Casualty Insurance Leader Softserve

Hadoop An Overview Sciencedirect Topics
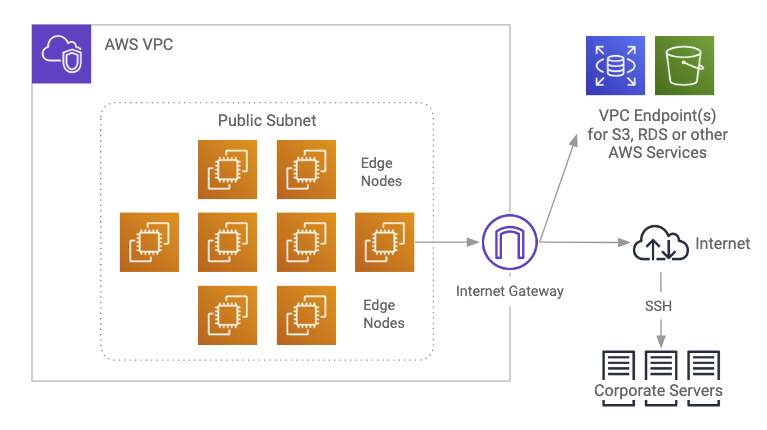
Cloudera Enterprise Reference Architecture For Aws Deployments 5 15 X Cloudera Documentation
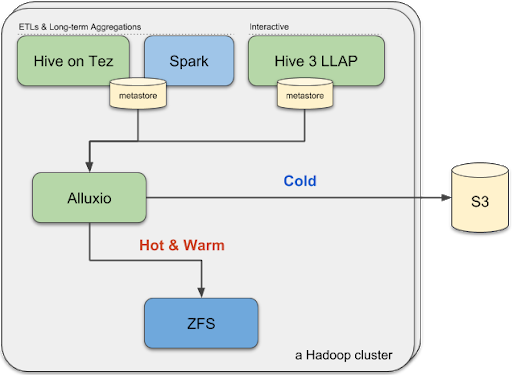
Accelerate Spark And Hive On Aws Simple Storage Service S3 Alluxio
3
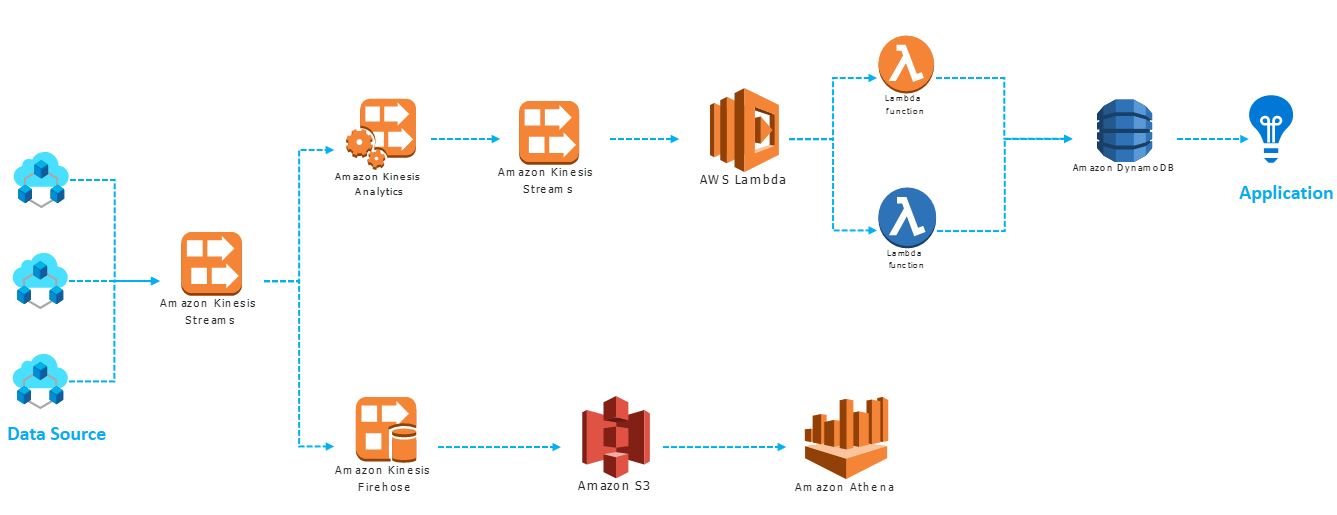
Aws Solution To Build Real Time Data Processing Application Using Kinesis Lambda Dynamodb S3 Greatlearning
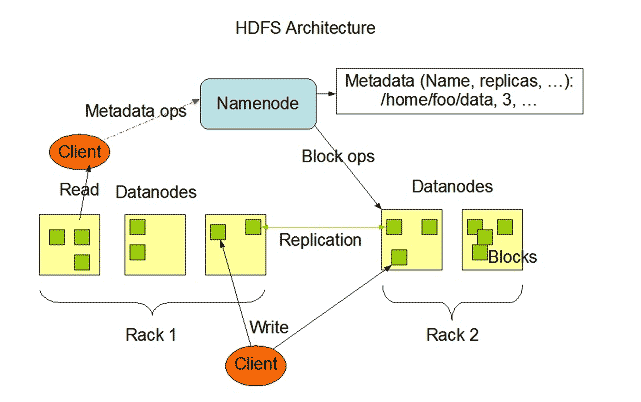
Learn The 10 Useful Difference Between Hadoop Vs Redshift
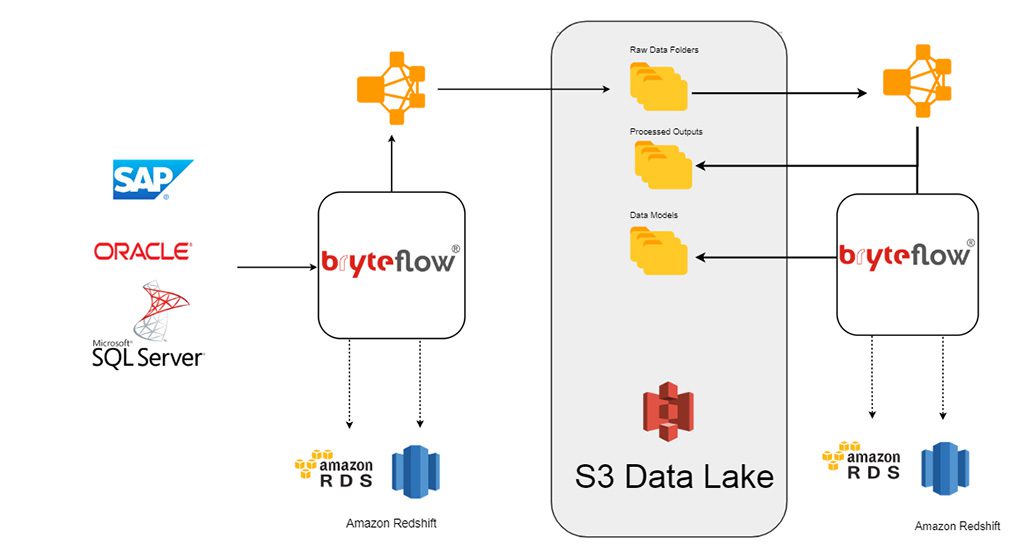
Why Hadoop Data Lakes Are Not The Modern Architect S Choice Bryteflow
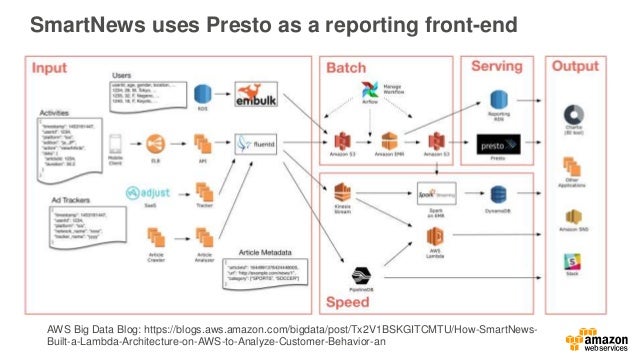
Apache Spark And The Hadoop Ecosystem On Aws

1 Introduction To Amazon Elastic Mapreduce Programming Elastic Mapreduce Book
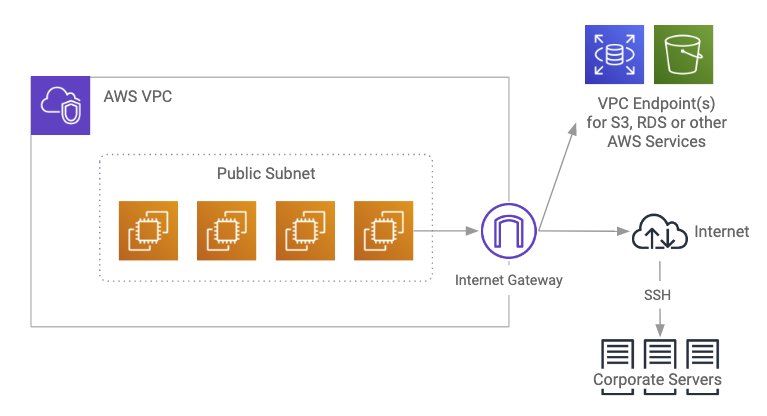
Cloudera Enterprise Reference Architecture For Aws Deployments 5 15 X Cloudera Documentation
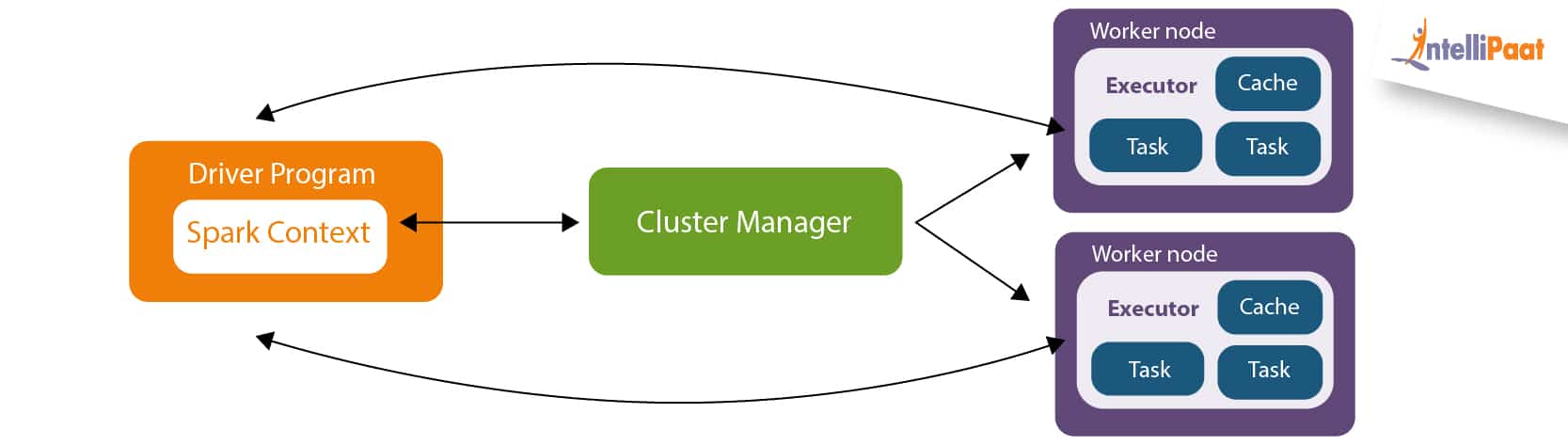
Apache Spark Architecture Apache Spark Framework Intellipaat

Data Lakes Without Hadoop
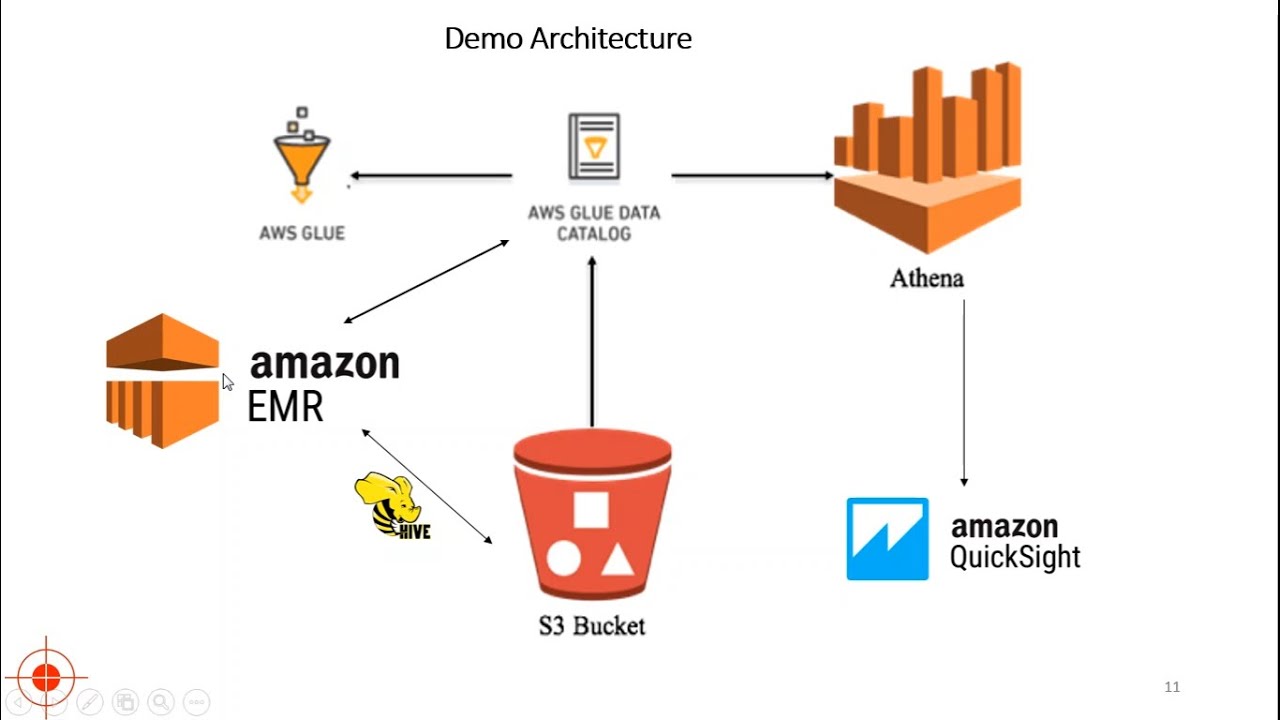
Hadoop On Aws Using Emr Tutorial S3 Athena Glue Quicksight Youtube
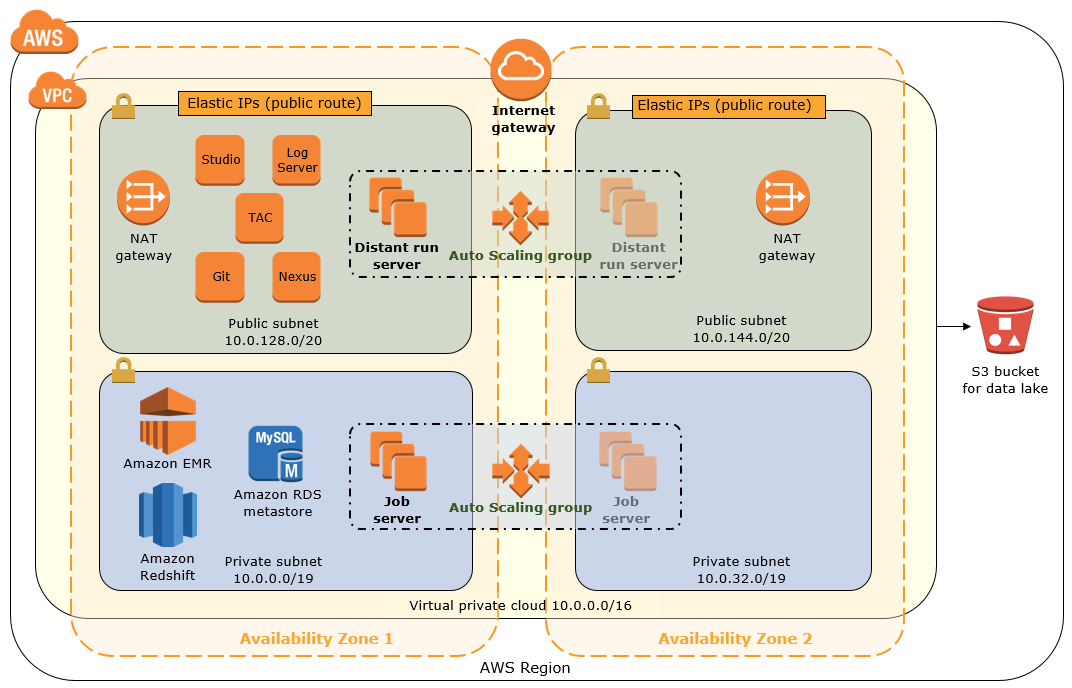
Data Lake With Talend Big Data Platform Quick Start
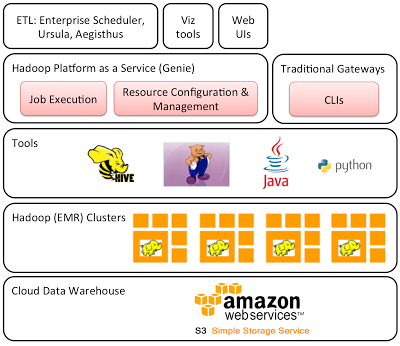
Hadoop Platform As A Service In The Cloud By Netflix Technology Blog Netflix Techblog

Aws Architecture Diagrams Google Search Aws Architecture Diagram Diagram Architecture Big Data Technologies

Elastic Map Reduce Hadoop Architecture S3 And Quick Options Youtube

Hadoop Architecture Explained What It Is And Why It Matters
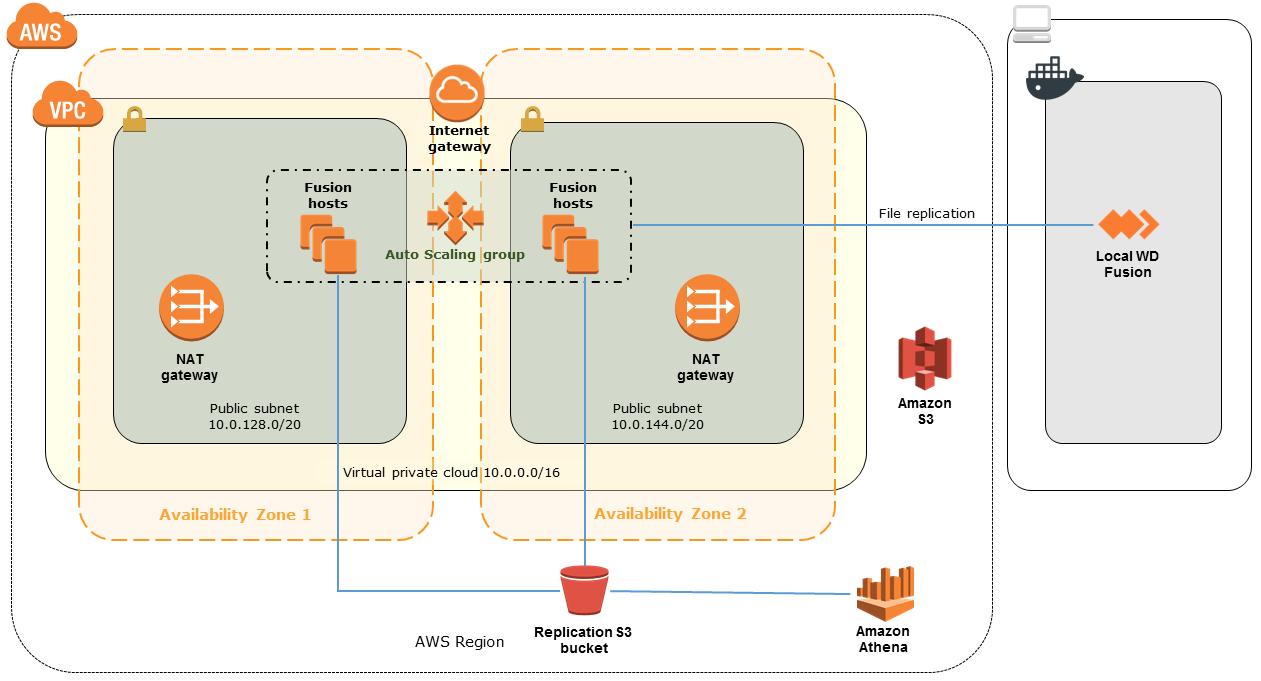
Hybrid Data Lake On Aws Quick Start

Amazon Emr Deep Dive Best Practices

Launching Your First Big Data Project On Aws Youtube
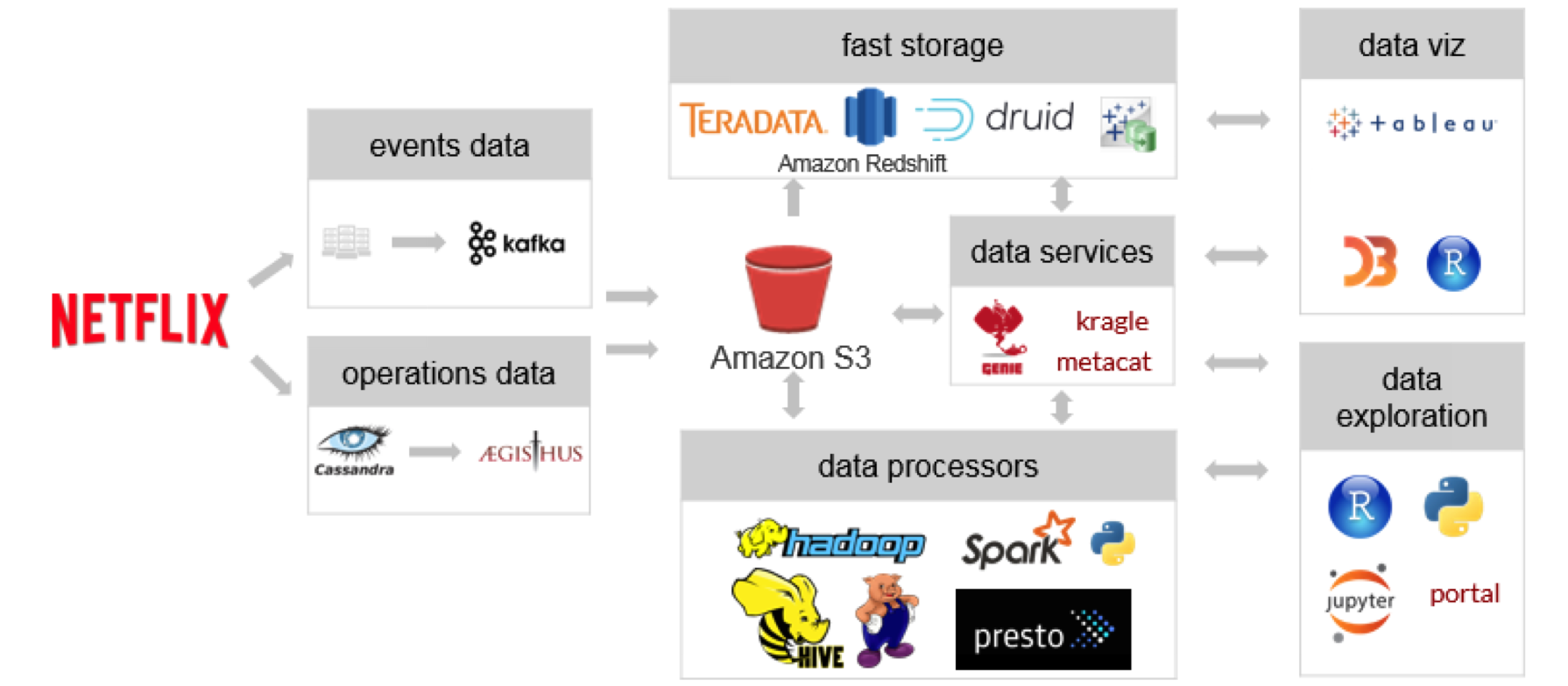
How Netflix Built Analytics In The Cloud With Tableau And Aws

Statistical Representation Of Data Using Hadoop Mapreduce On Aws Akshay Thorve

Getting Started With Amazon Elastic Mapreduce Cloud Academy
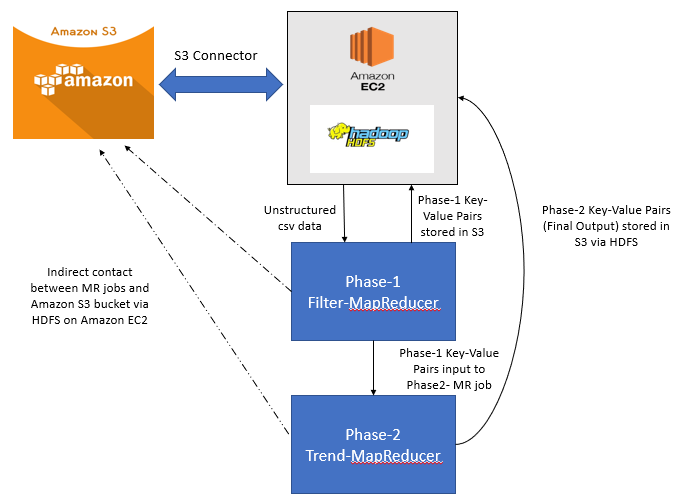
Map Reduce With Amazon Ec2 And S3 By Sanchit Gawde Medium

Ad Hoc Big Data Processing Made Simple With Serverless Mapreduce Aws Compute Blog

Introduction To Amazon Emr The Little Steps
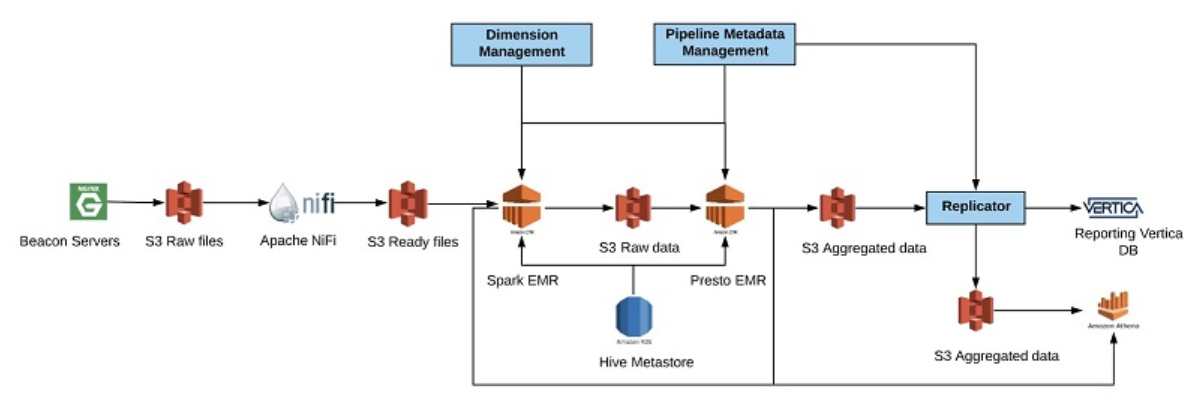
How Verizon Media Group Migrated From On Premises Apache Hadoop And Spark To Amazon Emr Aws Big Data Blog

Aws Emr Spark On Hadoop Scala Anshuman Guha

Nicole Givin Author At Cloud Technology Partners Page 25 Of 147

Uber S Big Data Platform 100 Petabytes With Minute Latency Uber Engineering Blog
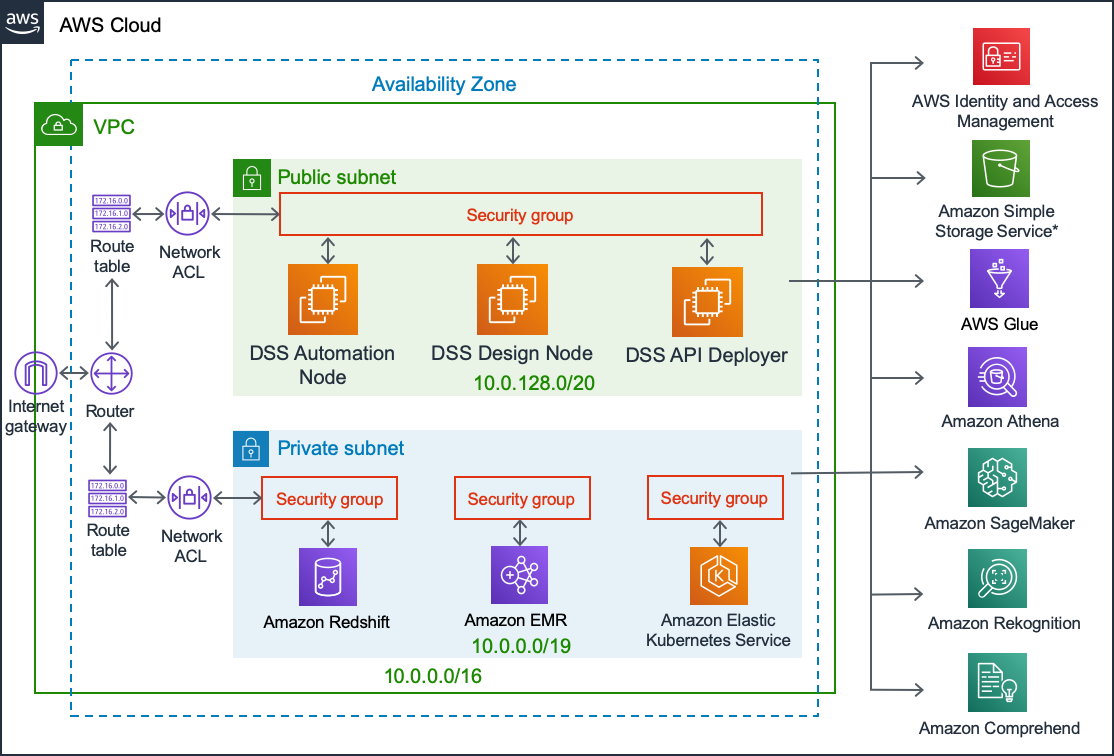
Reference Architecture Managed Compute On Eks With Glue And Athena Dataiku Dss 8 0 Documentation
Docs Cloudera Com Documentation Other Reference Architecture Pdf Cloudera Ref Arch Aws Pdf

Building For The Internet Of Things With Hadoop
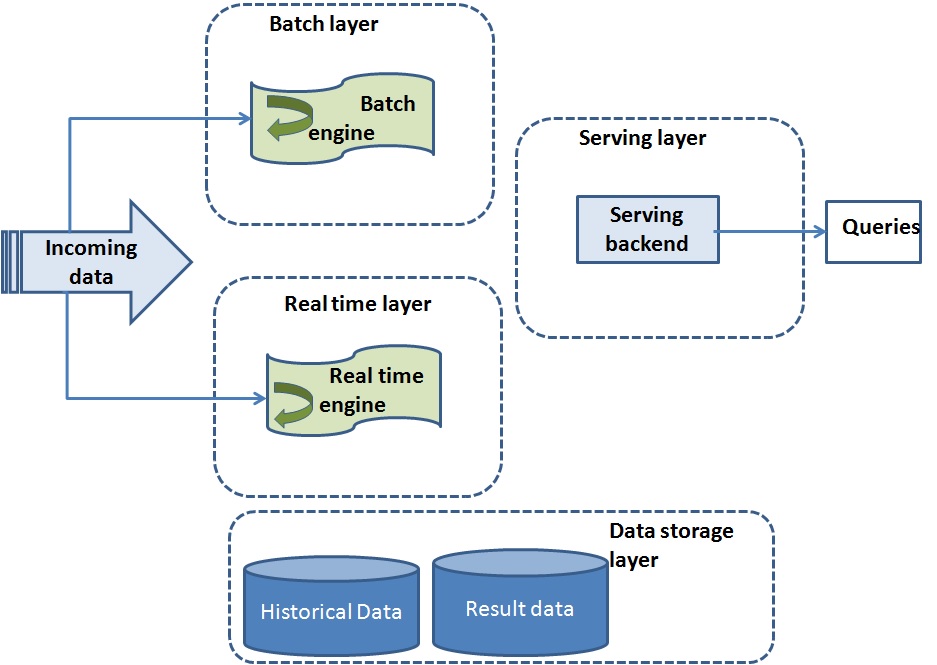
Real Time Big Data Pipeline With Hadoop Spark Kafka Whizlabs Blog
1
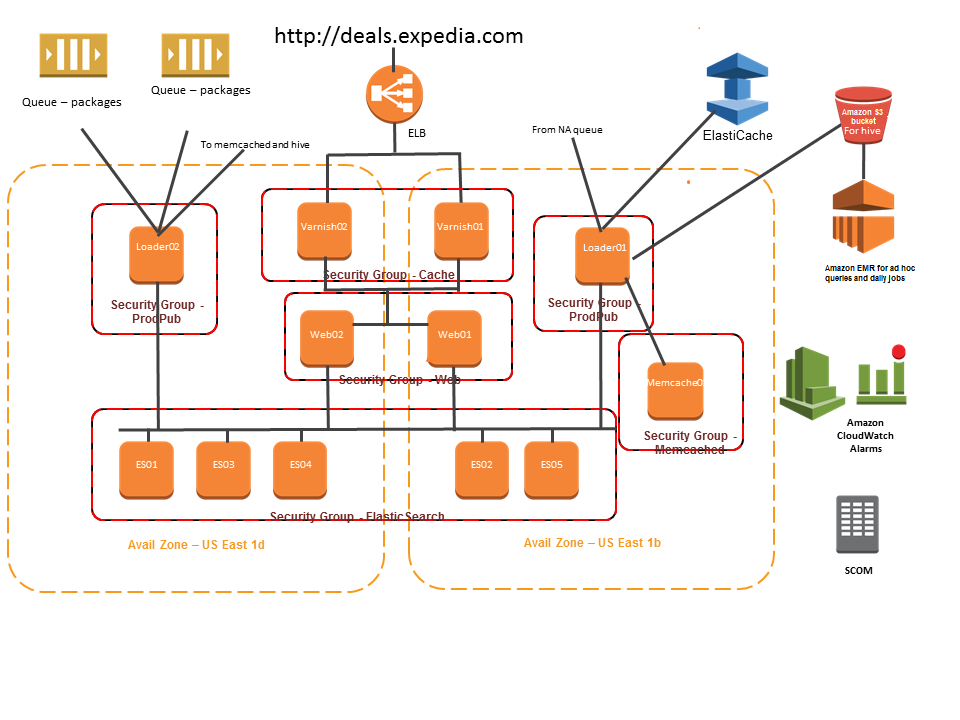
Expedia Case Study
An Overview Of Hadoop Mapreduce Architecture
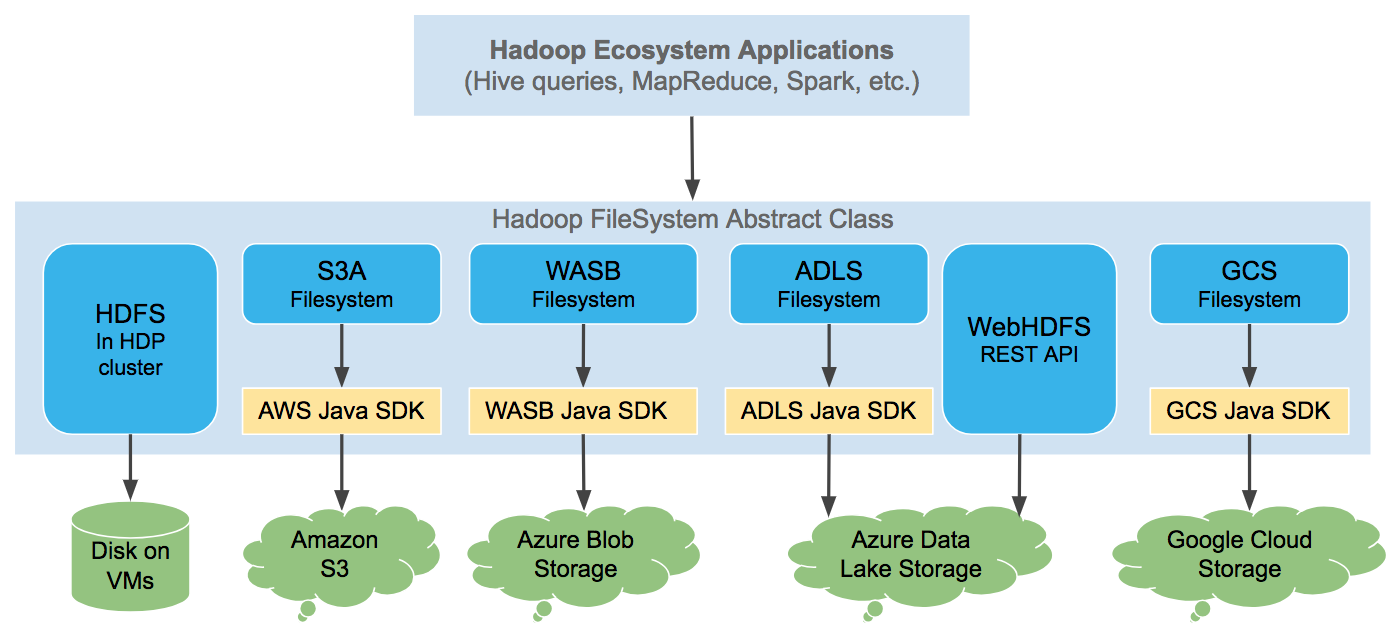
Chapter 2 The Cloud Storage Connectors Hortonworks Data Platform

Data Warehouse Migration To Aws Redshift Using Amazon Emr By Sanket Wagh Medium
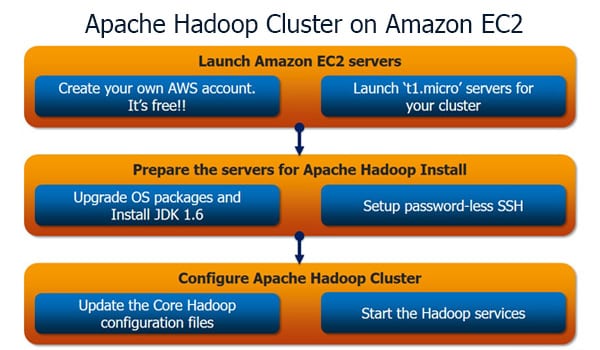
How To Install Apache Hadoop Cluster On Amazon Ec2 Tutorial Edureka
Aws Architecture Outline T Neumann Github Io

Amazon Glue For Etl In Data Processing Accenture
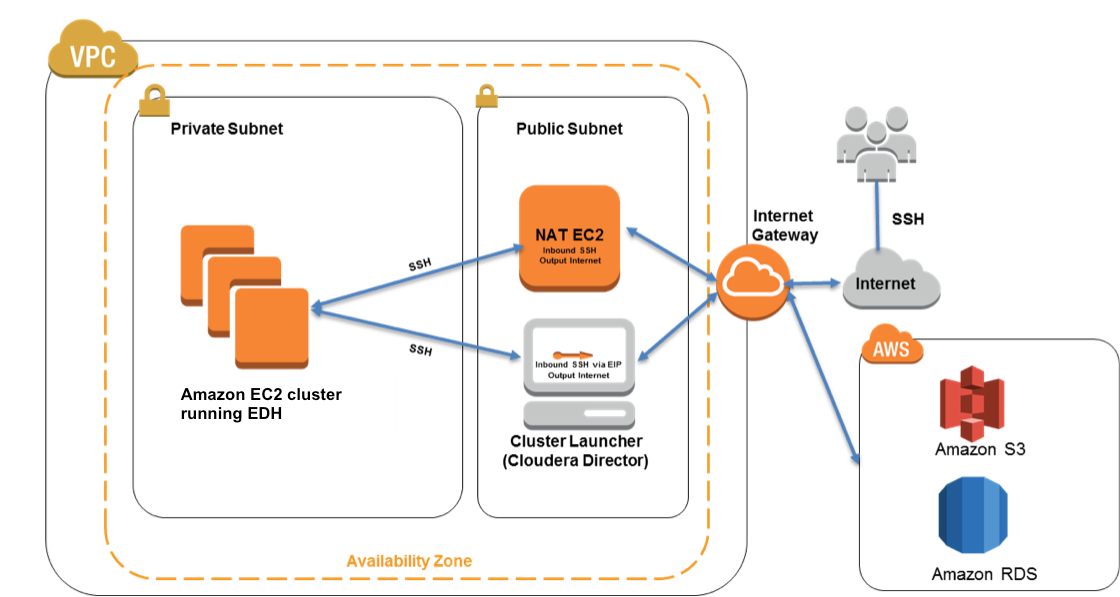
Cloudera Edh On Aws Quick Start
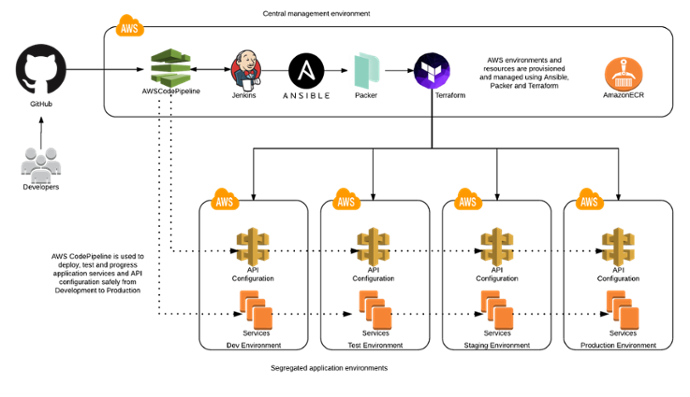
An Aws Centric Solution Architecture For Open Banking Contino Global Transformation Consultancy
Www Netapp Com Media Tr 4529 Pdf
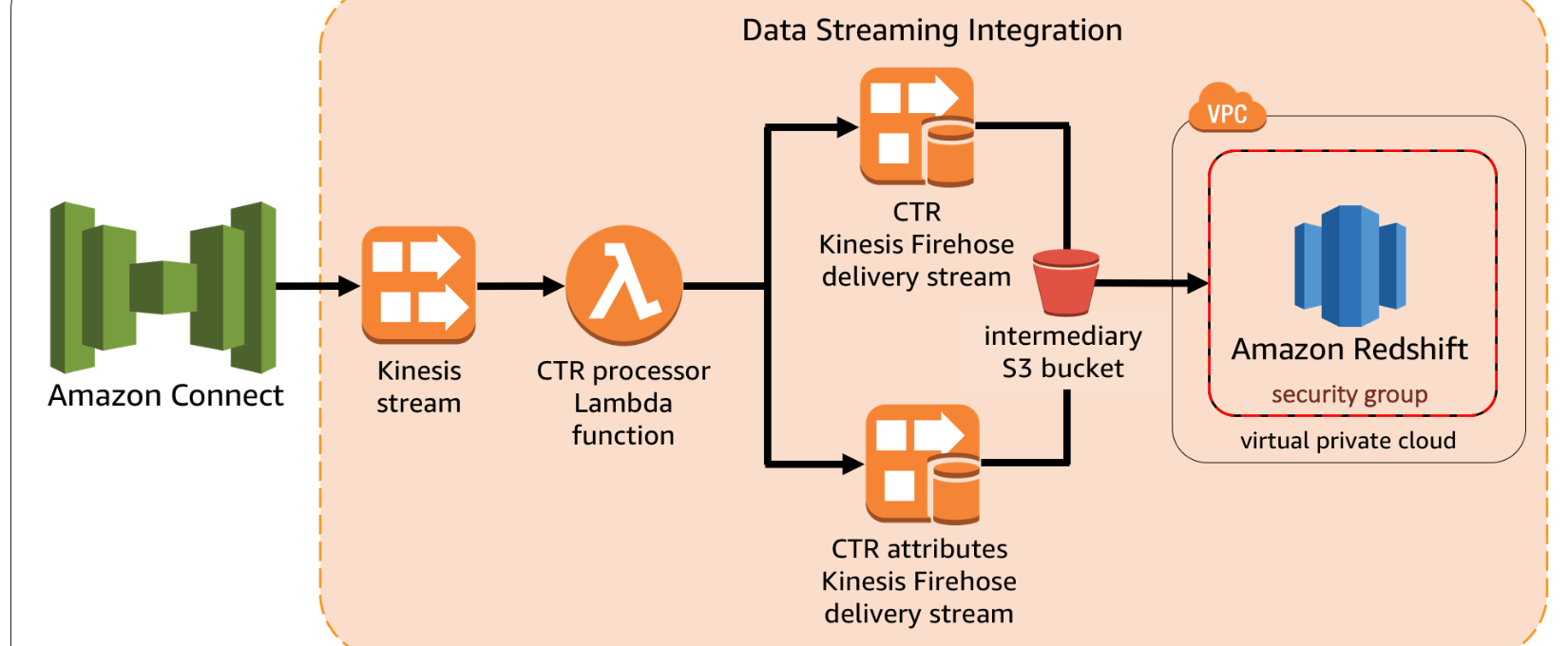
Setting The Stage To Design A Kinesis Application On Aws Cloud The High Level Architecture Blazeclan

Amazon Glue For Etl In Data Processing Accenture
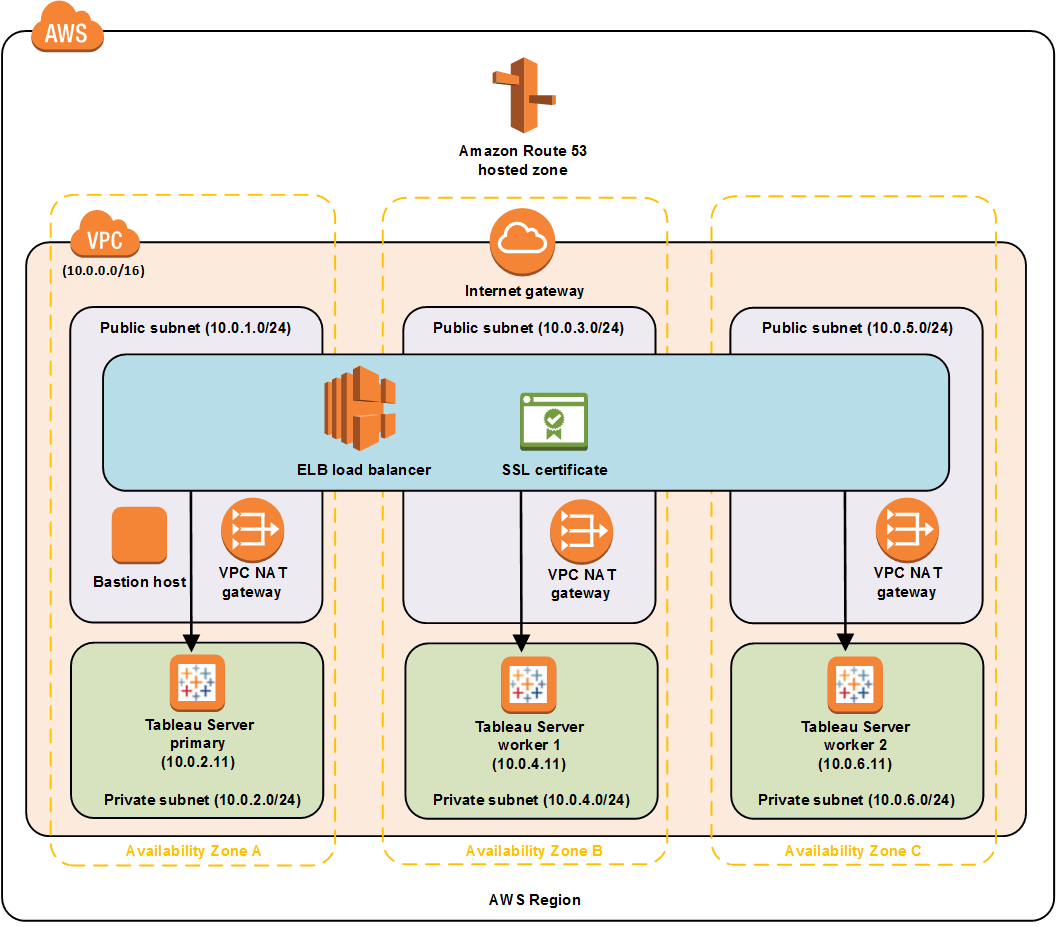
Aws Tableau On Amazon Web Services For Faster Analysis
3
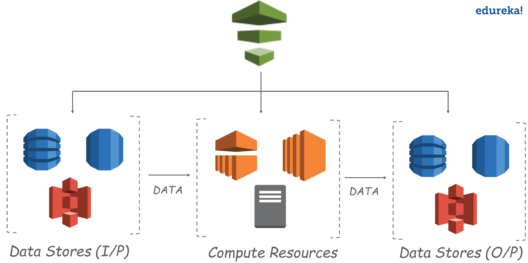
Aws Data Pipeline Tutorial Building A Data Pipeline From Scratch Edureka
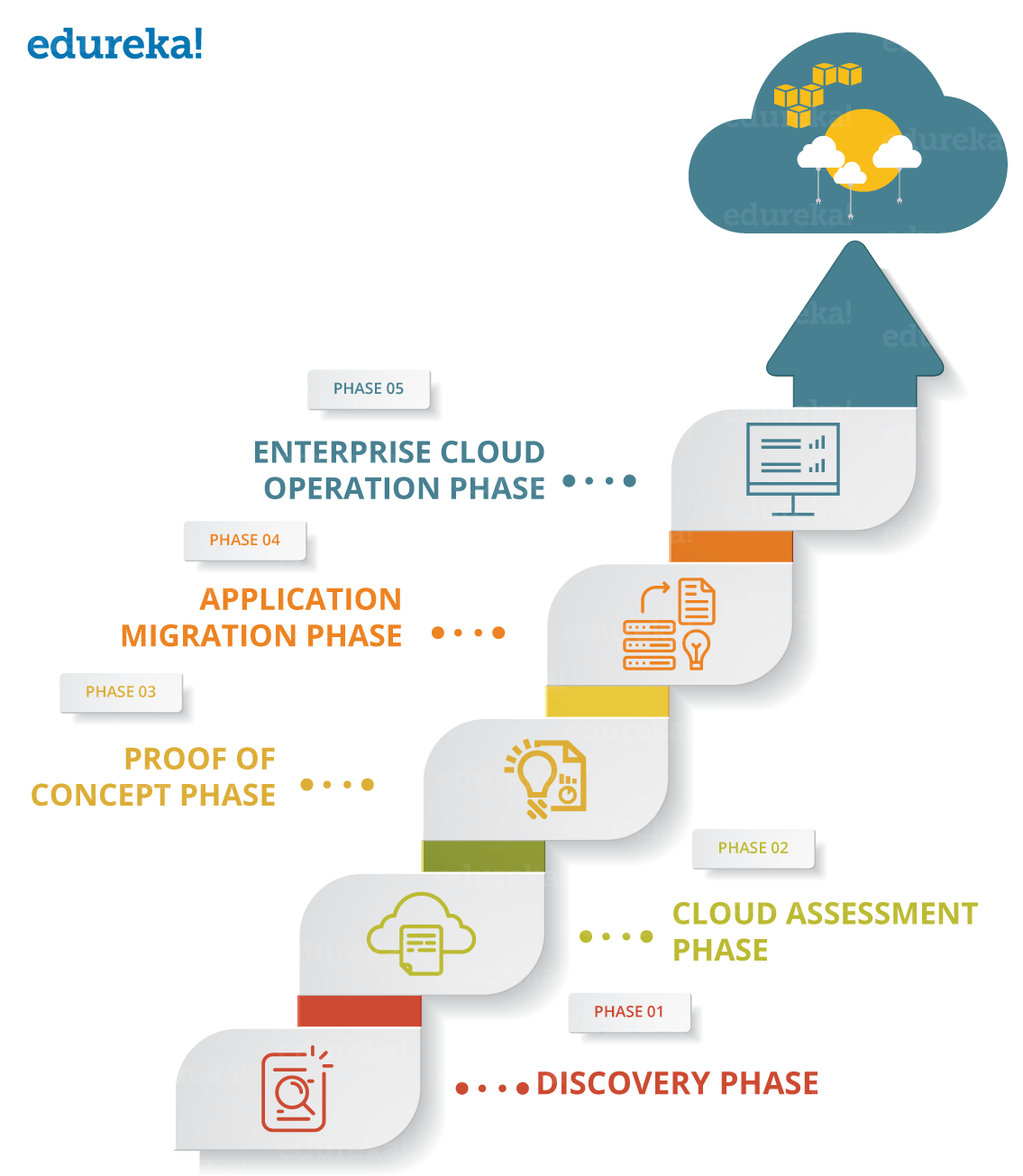
Aws Migration Migrating An On Premise Application To Cloud Edureka

Migrating Hdp Cluster To Amazon Emr To Save Costs

Nclouds Real Time Data Analytics Best Practices On Aws

Deploying Etl Platforms With Jenkins And Aws Cloudformation At A Large Financial Institution Head In The Cloud
Lambda Architecture With Apache Spark Dzone Big Data
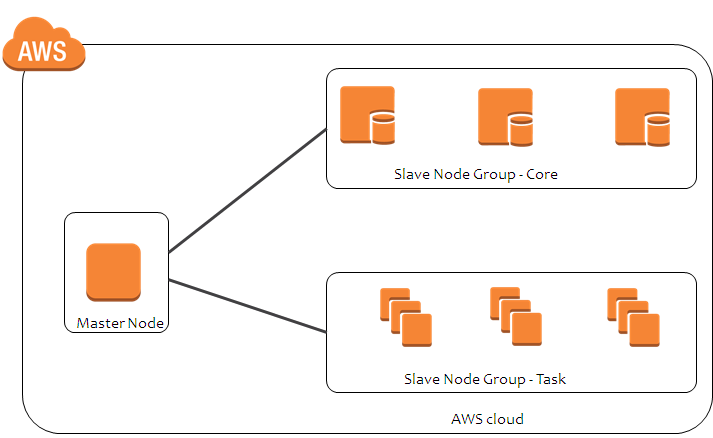
Amazon Emr Five Ways To Improve The Way You Use Hadoop

The Proposed Architecture Of Improved Prepost Algorithm On Aws Download Scientific Diagram

Image Title Software Architecture Diagram Diagram Architecture Up And Running

Hadoop Performance Evaluation By Benchmarking And Stress Testing With Terasort And Testdfsio By Rahul Nayak Yml Innovation Lab Medium
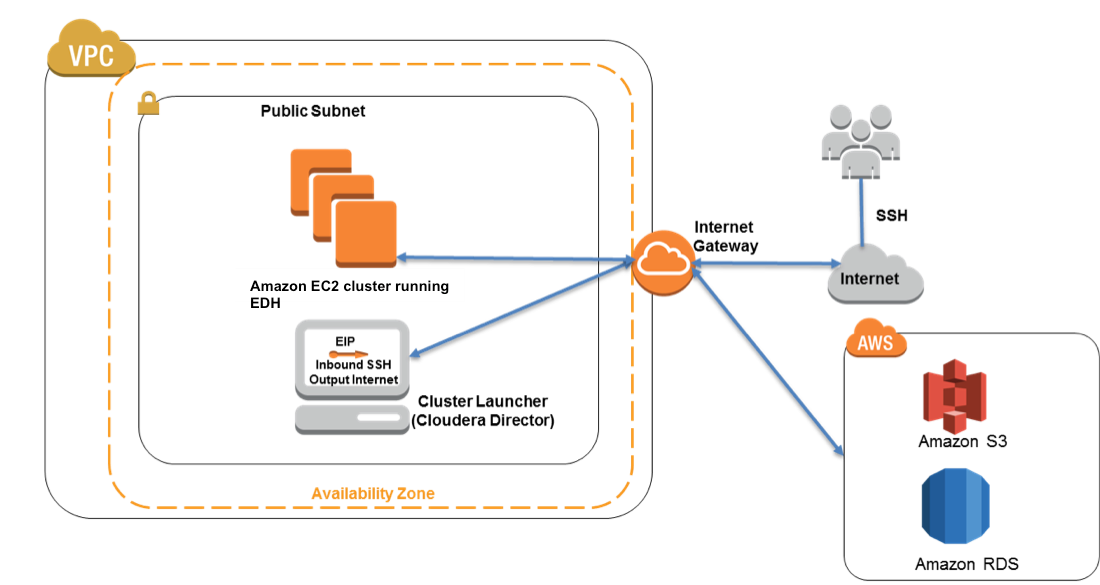
Architecture Cloudera Edh On Aws

Build A Data Lake Foundation With Aws Glue And Amazon S3 Aws Big Data Blog
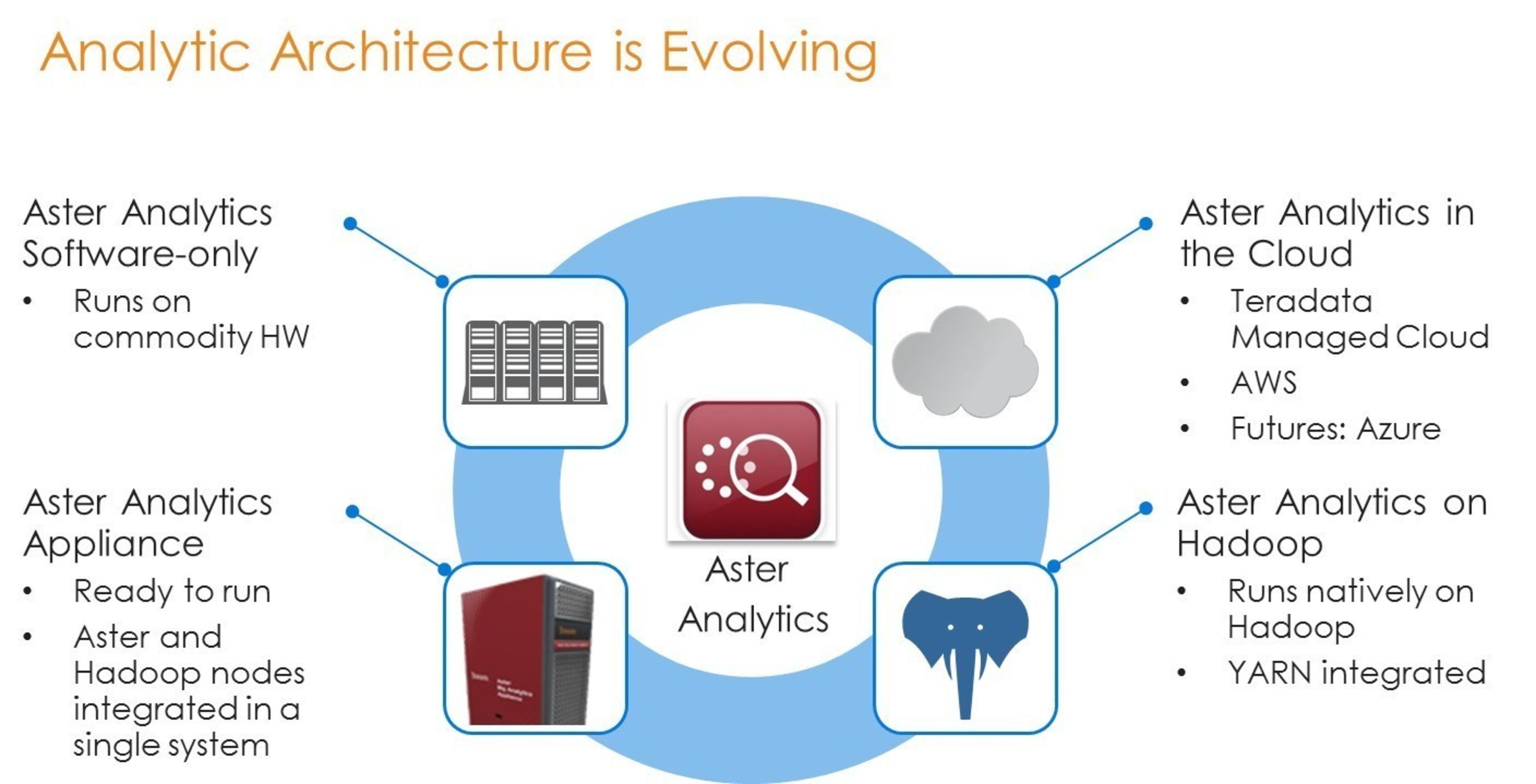
Teradata Aster Analytics Going Places On Hadoop And Aws

Low Latency Access On Trillions Of Records Finra S Architecture Using Apache Hbase On Amazon Emr With Amazon S3 Aws Big Data Blog
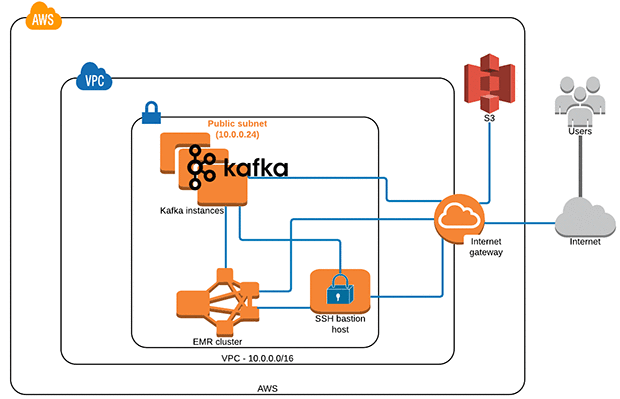
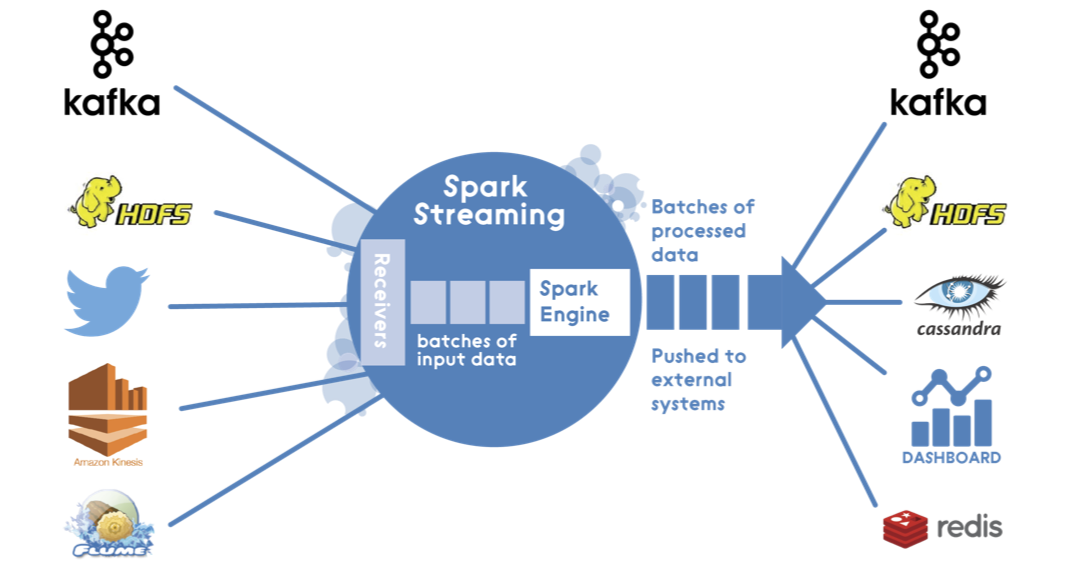
Real Time Stream Processing Using Apache Spark Streaming And Apache Kafka On Aws Aws Big Data Blog
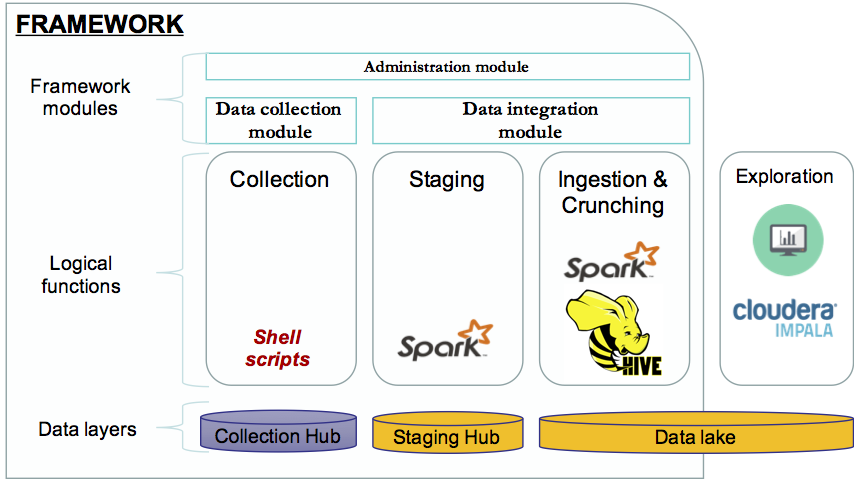
Hadoop Data Integration How To Streamline Your Etl Processes With Apache Spark

A Hadoop Based Cloud Data Center Architecture For Bigdata Analytics Download Scientific Diagram
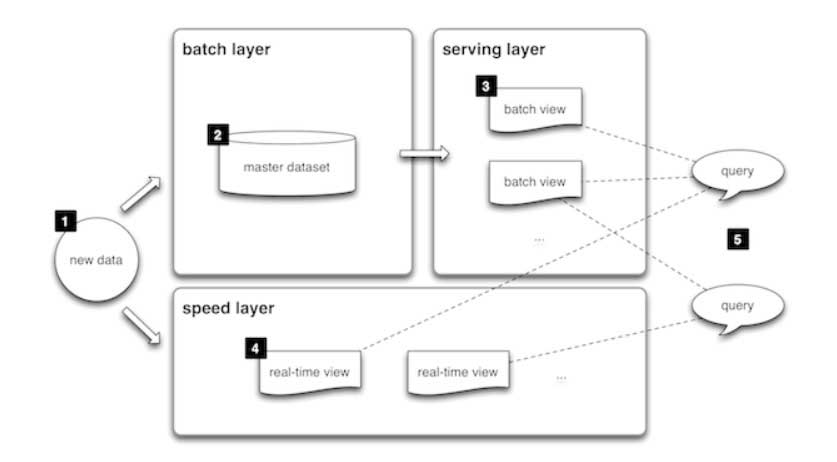
What Is Lambda Architecture Databricks

Hdfs Vs S3 Aws S3 Vs Hadoop Hdfs Youtube

What Is Hadoop

Big Data Analytics Powered By Hadoop Faction Inc
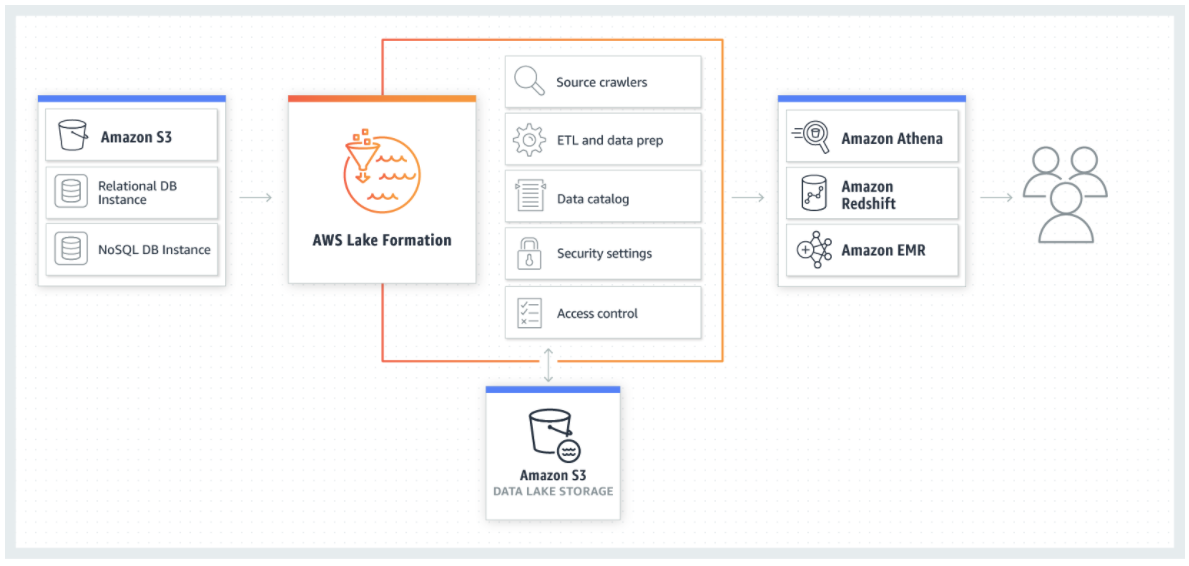
Big Data Reference Architecture

Migrate Your Hadoop Spark Workload To Amazon Emr And Architect It For
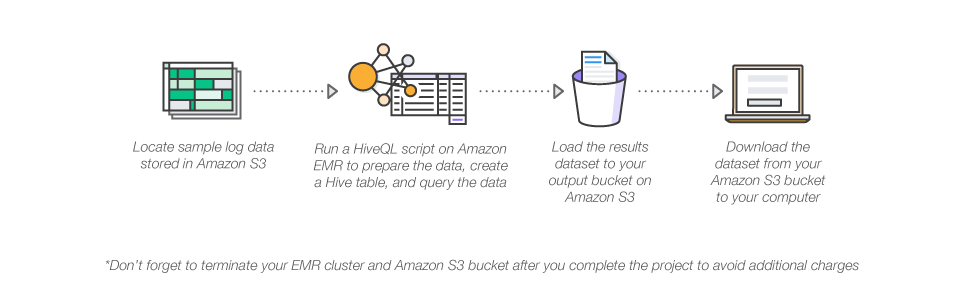
How To Analyze Big Data With Hadoop Amazon Web Services Aws

Setting Up A Hospitality Business Model On Aws
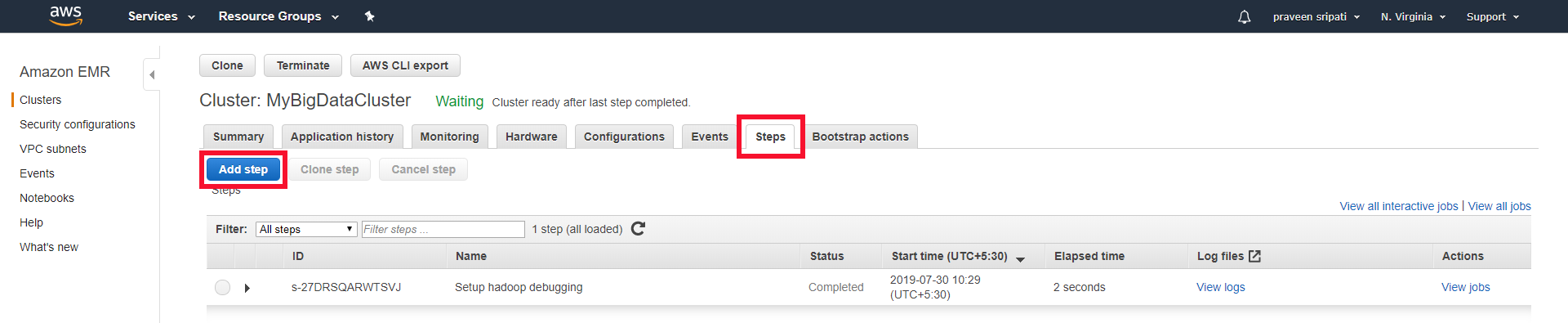
How To Create Hadoop Cluster With Amazon Emr Edureka

Apache Hadoop Architecture Explained In Depth Overview
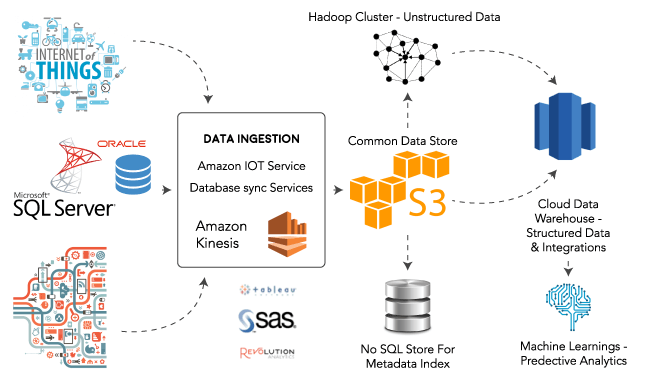
Bigdata Lakes On Aws Your Agile Modern Data Delivery Platform For Snowflake Bigquery Redshift Azure Pdw Instant Analytics

Welcome Aws Big Data Solution Overview
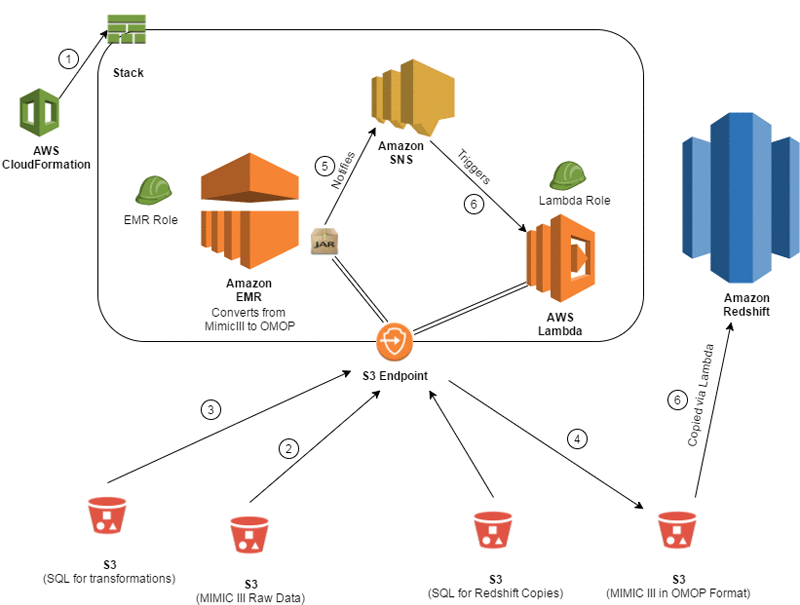
Build A Healthcare Data Warehouse Using Amazon Emr Amazon Redshift Aws Lambda And Omop Aws Big Data Blog
Q Tbn And9gctzungxay P2nifxg 2a4dsfxia Djzumtwcla04y0pvrekrudm Usqp Cau

Big Data Use Cases And Solutions In The Aws Cloud
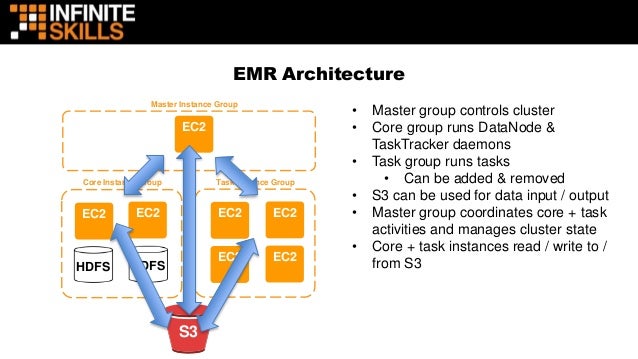
Hadoop In The Cloud With Aws Emr

Nasdaq S Architecture Using Amazon Emr And Amazon S3 For Ad Hoc Access To A Massive Data Set Aws Big Data Blog
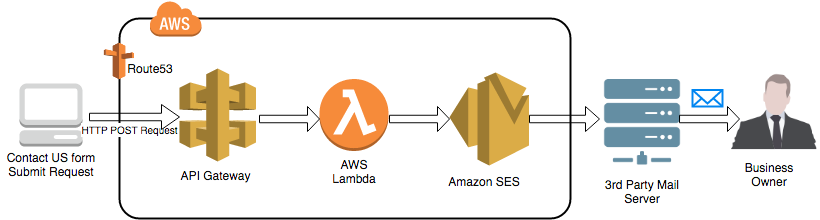
Aws Architecture 3 Major Components Of Aws Architecture Dataflair

Migrate Your Hadoop Spark Workload To Amazon Emr And Architect It For
Aws Architecture 3 Major Components Of Aws Architecture Dataflair

Enterprise Data Lake Architecture What To Consider When Designing

Migrate Your Hadoop Spark Workload To Amazon Emr And Architect It For

Running Apache Spark On Aws By Mariusz Strzelecki By Acast Tech Blog Acast Tech Medium

Tune Hadoop And Spark Performance With Dr Elephant And Sparklens On Amazon Emr Aws Big Data Blog



