Aws Hadoop Spark
Candidates will need Strong commercial Data Engineering skills including Hadoop, Spark, Hive and Python Experience developing/maintaining a Data Lake Streaming experience with Kafka Strong background working on complex distributed system Cloud experience with AWS Must have experience in design, implementation and DevOps.
Aws hadoop spark. Candidates will need Strong commercial Data Engineering skills including Hadoop, Spark, Hive and Python Experience developing/maintaining a Data Lake Streaming experience with Kafka Strong background working on complex distributed system Cloud experience with AWS Must have experience in design, implementation and DevOps. This course is answer for that Prerequisites Basic programming using Python or Scala or both;. Spark can run standalone, on Apache Mesos, or most frequently on Apache Hadoop Today, Spark has become one of the most active projects in the Hadoop ecosystem, with many organizations adopting Spark alongside Hadoop to process big data In 17, Spark had 365,000 meetup members, which represents a 5x growth over two years.
Candidates will need Strong commercial Data Engineering skills including Hadoop, Spark, Hive and Python Experience developing/maintaining a Data Lake Streaming experience with Kafka Strong background working on complex distributed system Cloud experience with AWS Must have experience in design, implementation and DevOps. In this case, we will have to upgrade sparkhadoop so that it uses a newer version of AWS SDK The latest release of spark is 301 and there is a pre built package with Hadoop 32 We can use this package to upgrade the spark version and use an updated AWS SDK which is compatible with this sparkhadoop package. AWS is here to help you migrate your big data and applications Our Apache Hadoop and Apache Spark to Amazon EMR Migration Acceleration Program provides two ways to help you get there quickly and with confidence Selfservice EMR migration guide Follow stepbystep instructions, get guidance on key design decisions, and learn best practices.
Hadoop and Spark come out of the box with first class support for S3 as another file system in addition to HDFS You can even create Hive tables for data stored in S3, which further simplifies accessing the data Configuring S3 You can access files in s3 with either Spark or Hadoop simply by using an S3 uri with the appropriate schema. YARNbased Ganglia metrics such as Spark and Hadoop are not available for EMR release versions 440 and 450 Use a later version to use these metrics Ganglia metrics for Spark generally have prefixes for YARN application ID and Spark DAGScheduler So prefixes follow this form. * Hadoop Is combination of Map Reduce which is used for data streaming in Hadoop Distributed File System(HDFS) * Spark It is a Data streaming framework uses Inline memory concept which is 100 times faster than Map Reduce * AWS Amazon Web.
In this case, we will have to upgrade sparkhadoop so that it uses a newer version of AWS SDK The latest release of spark is 301 and there is a pre built package with Hadoop 32 We can use this package to upgrade the spark version and use an updated AWS SDK which is compatible with this sparkhadoop package. Quick start guide There are a lot of topics to cover, and it may be best to start with the keystrokes needed to standup a cluster of four AWS instances running Hadoop and Spark using Pegasus Clone the Pegasus repository and set the necessary environment variables detailed in the ‘ Manual ’ installation of Pegasus Readme. Hadoop version 273 is the default version that is packaged with Spark, but unfortunately using temporary credentials to access S3 over the S3a protocol was not supported until version 280 You.
SageMaker Spark depends on hadoopaws281 To run Spark applications that depend on SageMaker Spark, you need to build Spark with Hadoop 28 However, if you are running Spark applications on EMR, you can use Spark built with Hadoop 27 Apache Spark currently distributes binaries built against Hadoop27, but not 28 See the Spark. Hadoop is a framework for the similar goal GCP and AWS is a platforms Think of them as a number of data centers all around the world full of servers that you can rent and use GCP and AWS use Spark and Hadoop in their systems, alongside other technologies. Apache Hadoop and Spark make it possible to generate genuine business insights from big data The Amazon cloud is natural home for this powerful toolset, providing a variety of services for running.
For AWS use EMR you can use EMR Studio. Migration Workshop Agenda This Mactores led Online Workshop jumpstarts your Apache Hadoop/Spark migration to Amazon EMR We recommend that your Apache Hadoop/Spark Admins, Data Engineers, and Infrastructure Engineers be present Your Analysts, Data Scientists, or ML Engineers can also attend. SageMaker Spark depends on hadoopaws281 To run Spark applications that depend on SageMaker Spark, you need to build Spark with Hadoop 28 However, if you are running Spark applications on EMR, you can use Spark built with Hadoop 27 Apache Spark currently distributes binaries built against Hadoop27, but not 28.
PaaS Cloud on GCP (or AWS) 2 PARTIALLYMANAGED Setup a Hadoop/Spark managed cloudcluster on GCP or AWS see setuphadoop folder in this Repo for instructions/scripts create a GCS (or AWS) bucket for input/output job data see example_datasets folder in this Repo for sample data files;. Hadoop, at it’s version # 1 was a combination of Map/Reduce compute framework and HDFS distributed file system We are now well into version 2 of hadoop and the reality is Map/Reduce is legacy Apache Spark, HBase, Flink and others are ruling the compute side of things. Amazon Web Services (AWS) is the best option for this use case AWS provides a managed solution for Hadoop called Elastic Map Reduce (EMR) EMR allows developers to quickly start Hadoop clusters,.
However, if you also want to access AWS S3 buckets via your Hadoop or Spark jobs, you can add your AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY credentials here But be aware that this is highly insecure because you are listing your credentials in plain text A better way might be to store credentials in environment variables and then pull them. Explore AWS EMR with Hadoop and Spark From the course Amazon Web Services Data Services Start my 1month free trial Buy this course ($999 *) Original course price was $2999 and now $999 for a. Python & Amazon Web Services Projects for ₹100 ₹400 Need to read JSON data from S3 and add some columns and write it S3 Hire a Hadoop Salesperson Browse Hadoop Jobs Post a Hadoop Project Learn more about Hadoop Hive AWS Glue Spark ETL Job.
Running Hadoop on AWS Amazon EMR is a managed service that lets you process and analyze large datasets using the latest versions of big data processing frameworks such as Apache Hadoop, Spark, HBase, and Presto on fully customizable clusters Easy to use You can launch an Amazon EMR cluster in minutes. Your Spark cluster will need a Hadoop version 2x or greater If you use the Spark EC2 setup scripts and maybe missed it, the switch for using something other than 10 is to specify hadoopmajorversion 2 (which uses CDH 42 as of this writing). Overview Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure thatHADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath For client side interaction, you can declare that relevant JARs must be.
This document demonstrates how to use sparklyr with an Cloudera Hadoop & Spark cluster Data are downloaded from the web and stored in Hive tables on HDFS across multiple worker nodes RStudio Server is installed on the master node and orchestrates the analysis in spark. Apache Spark on EMR EMR (Elastic Map Reduce) is an Amazonmanaged Hadoop distribution It runs on EC2 nodes and the hosts are initialized by installing data processing libraries (like Apache. Candidates will need Strong commercial Data Engineering skills including Hadoop, Spark, Hive and Python Experience developing/maintaining a Data Lake Streaming experience with Kafka Strong background working on complex distributed system Cloud experience with AWS Must have experience in design, implementation and DevOps.
1 Hadoop Basics 2 Hadoop Ecosystems overview 3 Hive Basics 4 Scala 5 Spark 6 AWS 7 Spark Setup 8 Practice Sessions 9 Assignments 10Project Execution. Another option is to install using a vendor such as Cloudera for Hadoop, or Spark for DataBricks, or run EMR/MapReduce processes in the cloud with AWS Extract pricing comparisons can be complicated to split out since Hadoop and Spark are run in tandem, even on EMR instances, which are configured to run with Spark installed. Candidates will need Strong commercial Data Engineering skills including Hadoop, Spark, Hive and Python Experience developing/maintaining a Data Lake Streaming experience with Kafka Strong background working on complex distributed system Cloud experience with AWS Must have experience in design, implementation and DevOps.
Download hadoopaws273jar and awsjavasdk174jar and save these inside some folder (eg /users/me/testspark) One thing to remember here is that if you use any other version, you'll be in agony Add these two lines in your sparkdefaultsconf file which you can find inside the spark installation path. Good knowledge about distributed file systems such as HDFS. For GCP use DataProc includes Jupyter notebook interface OR;.
In this case, we will have to upgrade sparkhadoop so that it uses a newer version of AWS SDK The latest release of spark is 301 and there is a pre built package with Hadoop 32 We can use this package to upgrade the spark version and use an updated AWS SDK which is compatible with this sparkhadoop package. Summary This document demonstrates how to use sparklyr with an Cloudera Hadoop & Spark cluster Data are downloaded from the web and stored in Hive tables on HDFS across multiple worker nodes RStudio Server is installed on the master node and orchestrates the analysis in spark. With this option, you can use the SAP HANA Spark Controller to allow SAP HANA to access cold data through the Spark SQL SDA adapter On AWS, you can use an AWS native service like Amazon EMR for the Hadoop cold tier storage location To use Amazon EMR with SAP HANA, see DLM on Amazon Elastic Map Reduce documentation from SAP.
Migration Workshop Agenda This Mactores led Online Workshop jumpstarts your Apache Hadoop/Spark migration to Amazon EMR We recommend that your Apache Hadoop/Spark Admins, Data Engineers, and Infrastructure Engineers be present Your Analysts, Data Scientists, or ML Engineers can also attend. Hadoop, at it’s version # 1 was a combination of Map/Reduce compute framework and HDFS distributed file system We are now well into version 2 of hadoop and the reality is Map/Reduce is legacy Apache Spark, HBase, Flink and others are. Hadoop and Spark come out of the box with first class support for S3 as another file system in addition to HDFS You can even create Hive tables for data stored in S3, which further simplifies accessing the data Configuring S3 You can access files in s3 with either Spark or Hadoop simply by using an S3 uri with the appropriate schema.
Apache Spark includes several libraries to help build applications for machine learning (MLlib), stream processing (Spark Streaming), and graph processing (GraphX) These libraries are tightly integrated in the Spark ecosystem, and they can be leveraged out of the box to address a variety of use cases. Apache™ Hadoop® is an open source software project that can be used to efficiently process large datasets Instead of using one large computer to process and store the data, Hadoop allows clustering commodity hardware together to analyze massive data sets in parallel. In this case, we will have to upgrade sparkhadoop so that it uses a newer version of AWS SDK The latest release of spark is 301 and there is a pre built package with Hadoop 32 We can use this package to upgrade the spark version and use an updated AWS SDK which is compatible with this sparkhadoop package.
Moving analytics applications like Apache Spark and Apache Hadoop from onpremises data centers to a new AWS Cloud environment Many customers have concerns about the viability of distribution vendors or a purely opensource software approach, and they. Apache Spark Cluster Setup with Flintrock Start by installing Flintrock either on your workstation or on any AWS server used for operations (I would recommend the latter) Continue by using the. The following procedure creates a cluster with Spark installed using Quick Options in the EMR console Use Advanced Options to further customize your cluster setup, and use Step execution mode to programmatically install applications and then execute custom applications that you submit as steps With either of these advanced options, you can choose to use AWS Glue as your Spark SQL metastore.
Hadoop is a framework for the similar goal GCP and AWS is a platforms Think of them as a number of data centers all around the world full of servers that you can rent and use GCP and AWS use Spark and Hadoop in their systems, alongside other technologies. Apache Spark is a distributed processing framework and programming model that helps you do machine learning, stream processing, or graph analytics using Amazon EMR clusters Similar to Apache Hadoop, Spark is an opensource, distributed processing system commonly used for big data workloads. Explore AWS EMR with Hadoop and Spark 5m 15s Run Spark job on a Jupyter Notebook on AWS EMR 4m 1s 8 Data Lake with AWS Services 8 Data Lake with AWS Services Understand a data lake pattern with.
Overview Apache Hadoop’s hadoopaws module provides support for AWS integration applications to easily use this support To include the S3A client in Apache Hadoop’s default classpath Make sure thatHADOOP_OPTIONAL_TOOLS in hadoopenvsh includes hadoopaws in its list of optional modules to add in the classpath For client side interaction, you can declare that relevant JARs must be. 1 Hadoop Basics 2 Hadoop Ecosystems overview 3 Hive Basics 4 Scala 5 Spark 6 AWS 7 Spark Setup 8 Practice Sessions 9 Assignments 10Project Execution. To simplify the problem, you are free to compile your code locally, produce an uber/shaded JAR, SCP to any sparkclient in AWS, then run sparksubmit master yarn class However, if you want to just Spark against EC2 locally, then you can set a few properties programmatically Spark submit YARN mode HADOOP_CONF_DIR contents.
Amazon Web Services (AWS) is the best option for this use case I am going to execute a Spark job on a Hadoop cluster in EMR My goal will be to compute average comment length for each star. Plus, learn how to run opensource processing tools such as Hadoop and Spark on AWS and leverage new serverless data services, including Athena serverless queries and the autoscaling version of the Aurora relational database service, Aurora Serverless Topics include Benefits of AWS;. Python & Amazon Web Services Projects for ₹100 ₹400 Need to read JSON data from S3 and add some columns and write it S3 Hire a Hadoop Salesperson Browse Hadoop Jobs Post a Hadoop Project Learn more about Hadoop Hive AWS Glue Spark ETL Job.
If you are using PySpark to access S3 buckets, you must pass the Spark engine the right packages to use, specifically awsjavasdk and hadoopaws It’ll be important to identify the right package version to use As of this writing awsjavasdk ’s 174 version and hadoopaws ’s 277 version seem to work well. Are you familiar with Big Data Technologies such as Hadoop and Spark and planning to understand how to build Big Data pipelines leveraging pay as you go model of cloud such as AWS?. However, if you also want to access AWS S3 buckets via your Hadoop or Spark jobs, you can add your AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY credentials here But be aware that this is highly insecure because you are listing your credentials in plain text A better way might be to store credentials in environment variables and then pull them.
In a very short span of time Apache Hadoop has moved from an emerging technology to an established solution for Big Data problems faced by today’s enterprises Also, from its launch in 06, Amazon Web Services (AWS) has become synonym to Cloud Computing CIA’s recent contract with Amazon to build a private cloud service inside the CIA’s data centers is the proof of growing popularity and reliability of AWS as a Cloud Computing vendor to various organizations. Apache Hadoop and Spark make it possible to generate genuine business insights from big data The Amazon cloud is natural home for this powerful toolset, providing a variety of services for running largescale dataprocessing workflows. Explore AWS EMR with Hadoop and Spark 5m 15s Run Spark job on a Jupyter Notebook on AWS EMR 4m 1s 8 Data Lake with AWS Services 8 Data Lake with AWS Services Understand a data lake pattern with.
File storage with S3, Glacier, EBS, and EFS. Https//trendytechin/courses/bigdataonlinetraining/Sumit's LinkedIn https//wwwlinkedincom/in/bigdatabysumit/contact 91 If you have always. Hadoop and Spark Metrics in Ganglia Ganglia reports Hadoop metrics for each instance The various types of metrics are prefixed by category distributed file system (dfs*), Java virtual machine (jvm*), MapReduce (mapred*), and remote procedure calls (rpc*).
Spark prebuilt for Apache Hadoop Spark comes with a script called sparksubmit which we will be using to submit our job to the cluster.

Sf Data Weekly Kafka 1 0 Spark S Future Pipelines With Airflow Aws Lambda Revue
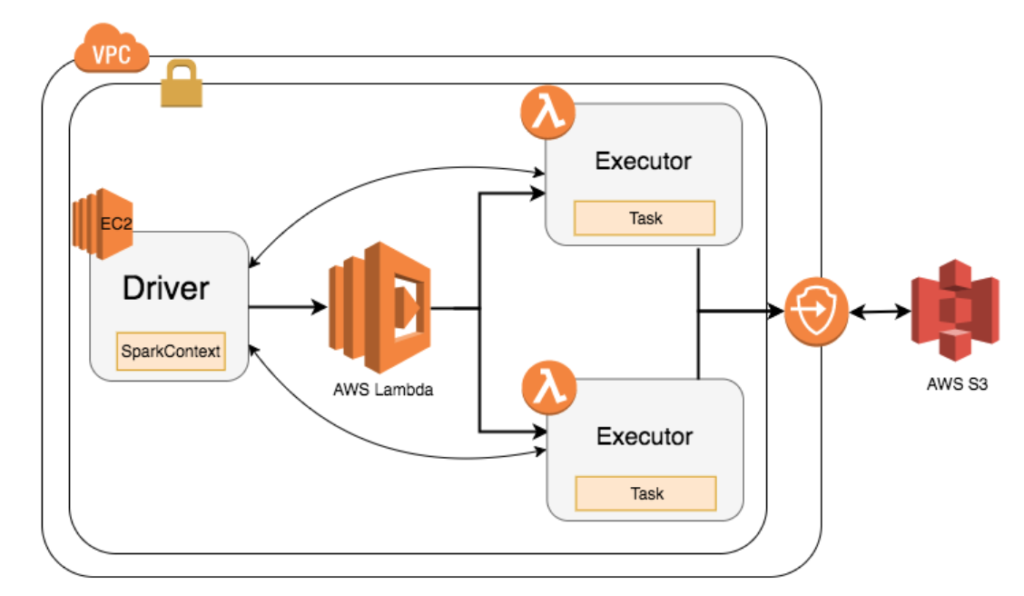
Qubole Announces Apache Spark On Aws Lambda

Beginners Guide To Pyspark How To Set Up Apache Spark On Aws
Aws Hadoop Spark のギャラリー
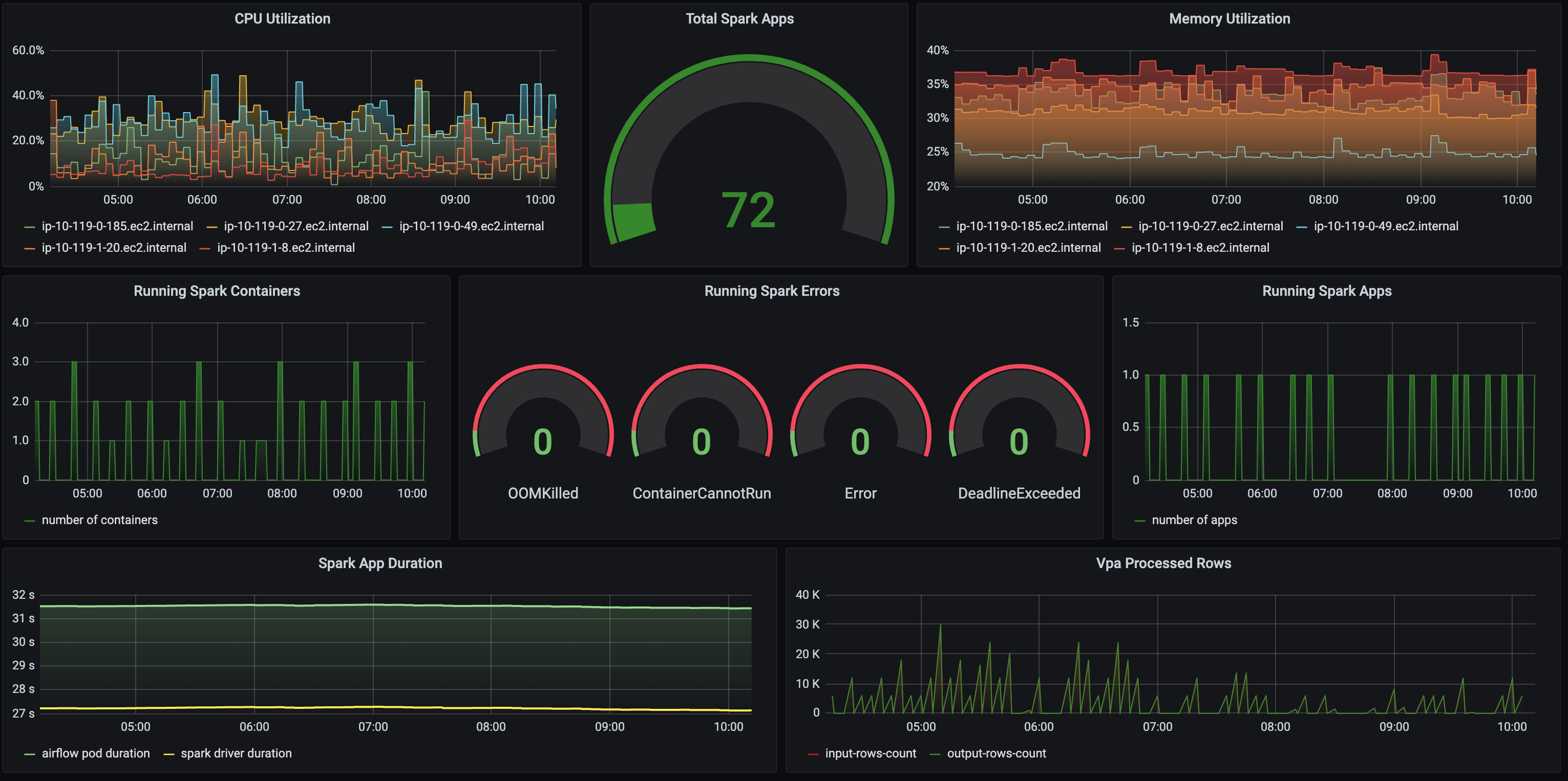
Migrating Apache Spark Workloads From Aws Emr To Kubernetes By Dima Statz Itnext
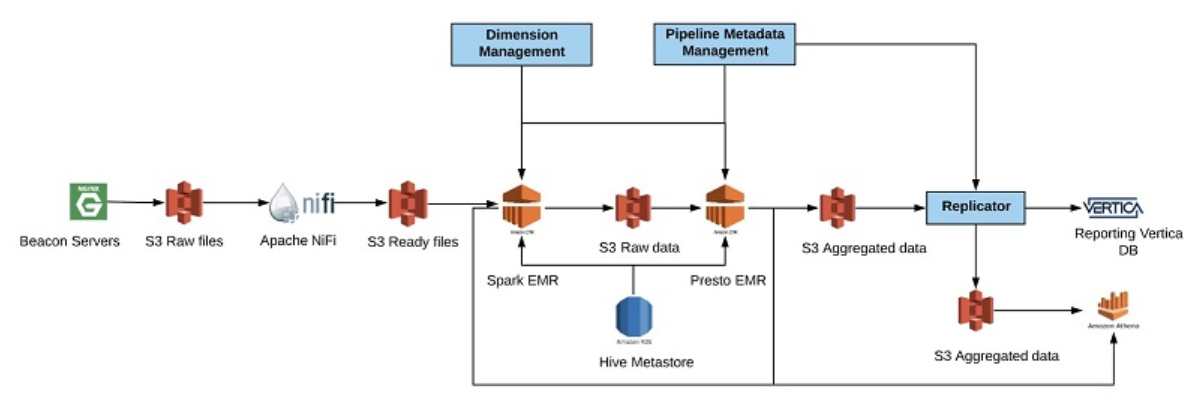
How Verizon Media Group Migrated From On Premises Apache Hadoop And Spark To Amazon Emr Aws Big Data Blog

Apache Spark Unified Analytics Engine For Big Data
Aws Emr As An Ad Hoc Spark Development Environment Trulia S Blog

Hadoop Vs Spark A Head To Head Comparison Logz Io

Orchestrate Apache Spark Applications Using Aws Step Functions And Apache Livy Aws Big Data Blog

Apache Spark Instaclustr

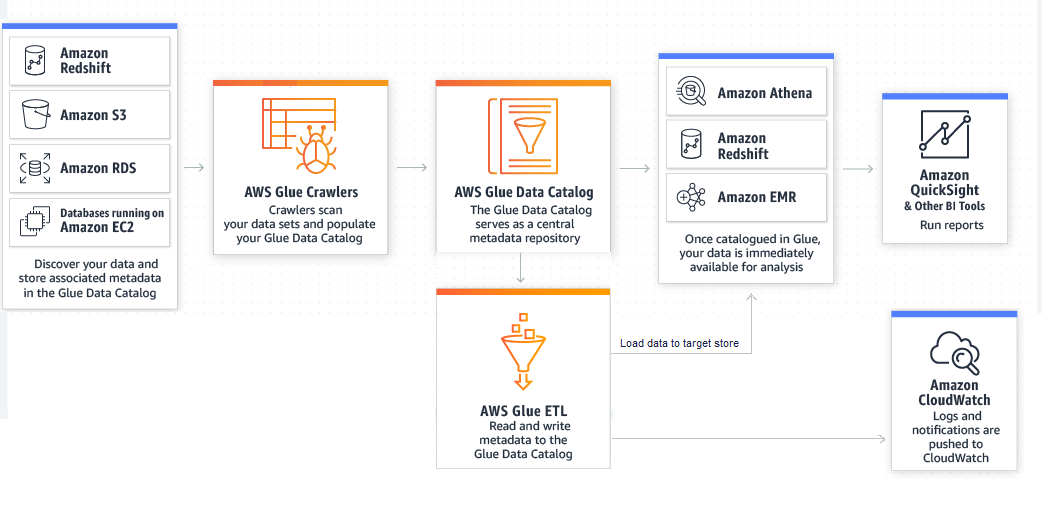
Solving Big Data Problems In The Cloud With Aws Glue And Apache Spark Softcrylic

A Terraform Module For Amazon Elastic Mapreduce Azavea
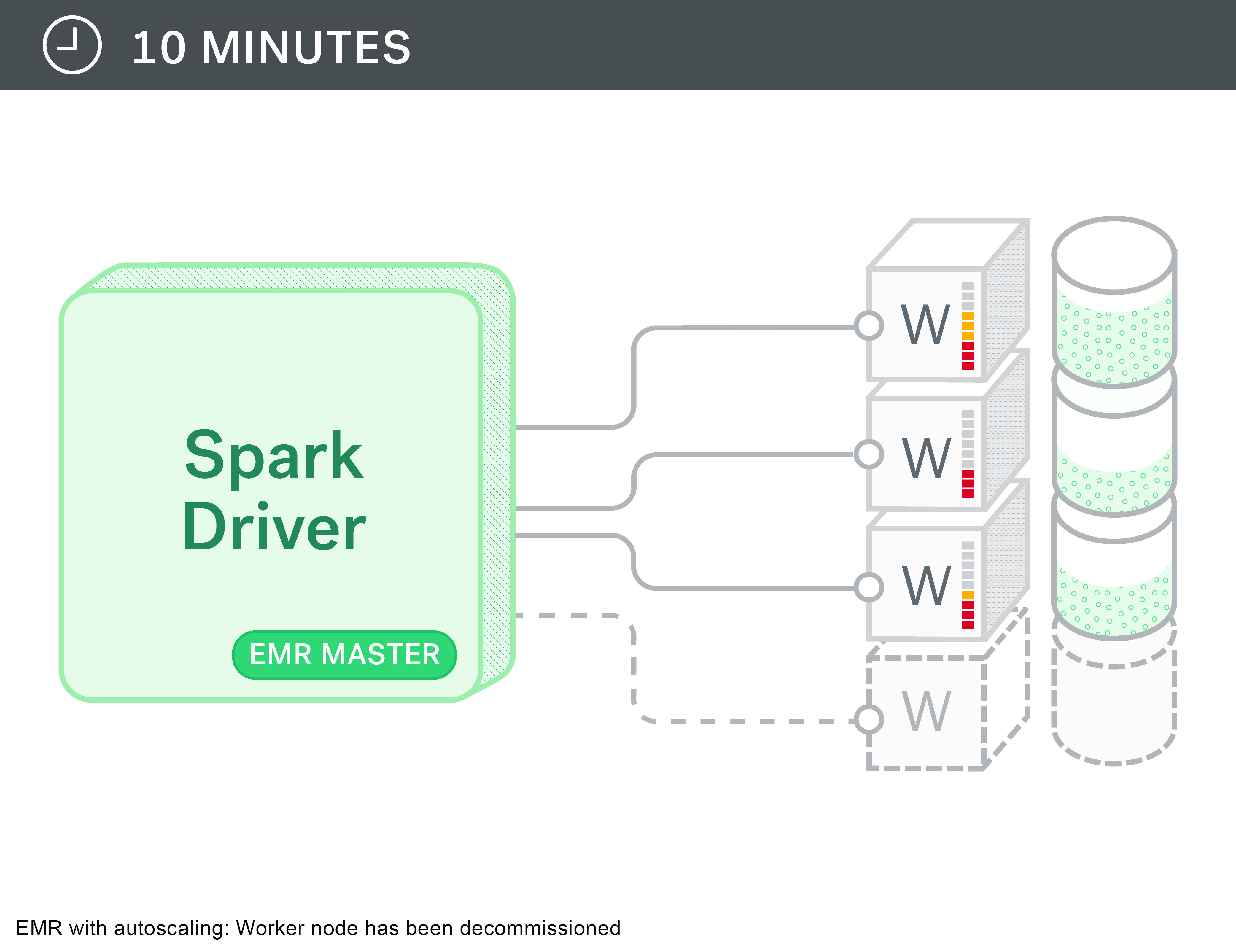
How Drop Used The Amazon Emr Runtime For Apache Spark To Halve Costs And Get Results 5 4 Times Faster Aws Big Data Blog

Tune Hadoop And Spark Performance With Dr Elephant And Sparklens On Amazon Emr Aws Big Data Blog

What Is Apache Spark Introduction To Apache Spark And Analytics Aws

Insights About Data Engineering Stream Analytics Iot And Data Processing
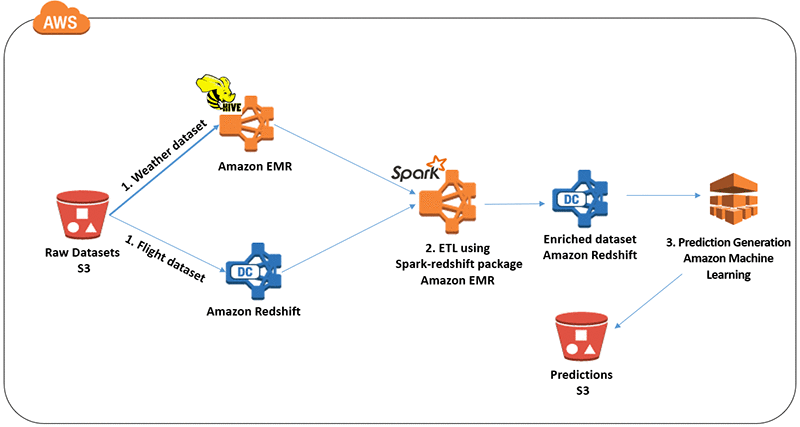
Powering Amazon Redshift Analytics With Apache Spark And Amazon Machine Learning Aws Big Data Blog

Amazon Emr Vs Apache Spark What Are The Differences

Migrating Apache Spark Workloads From Aws Emr To Kubernetes By Dima Statz Itnext
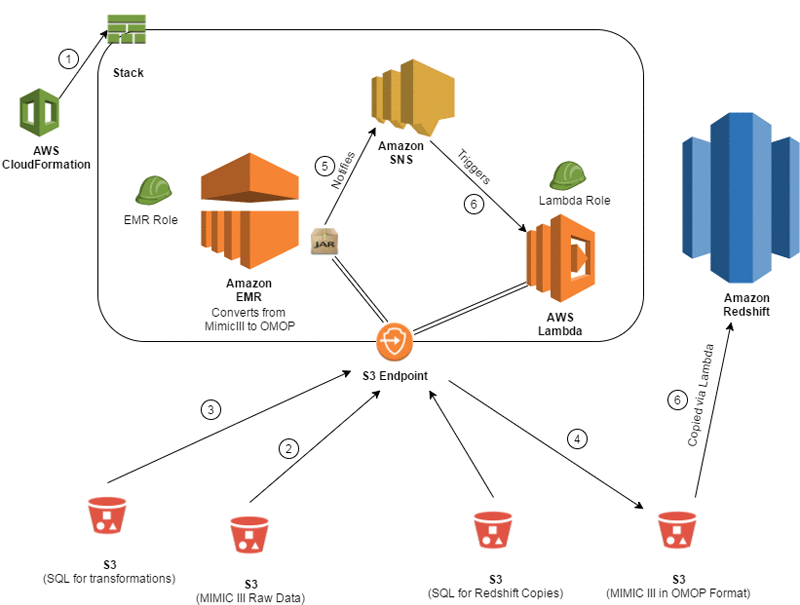
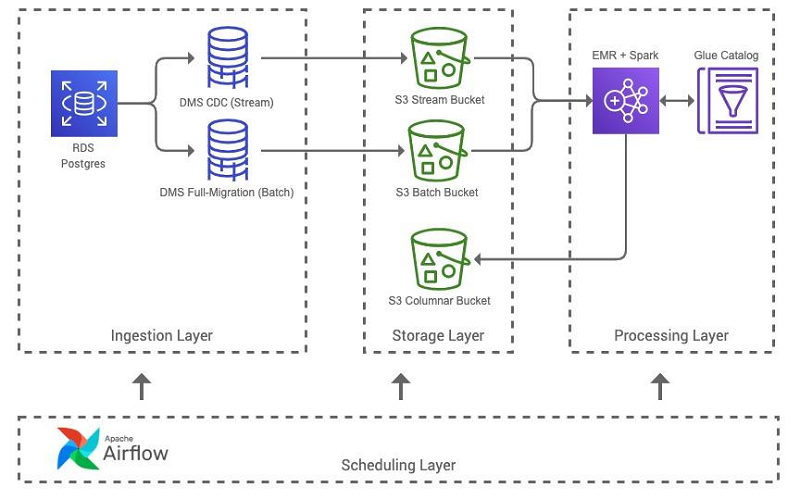
Build A Healthcare Data Warehouse Using Amazon Emr Amazon Redshift Aws Lambda And Omop Aws Big Data Blog

Build A Concurrent Data Orchestration Pipeline Using Amazon Emr And Apache Livy Aws Big Data Blog

Aws Emr Vs Ec2 Vs Spark Vs Glue Vs Sagemaker Vs Redshift Stentertainment

Spark And Snowflake Part 1 Why Spark Snowflake Blog

How Drop Used The Amazon Emr Runtime For Apache Spark To Halve Costs And Get Results 5 4 Times Faster Itcareersholland
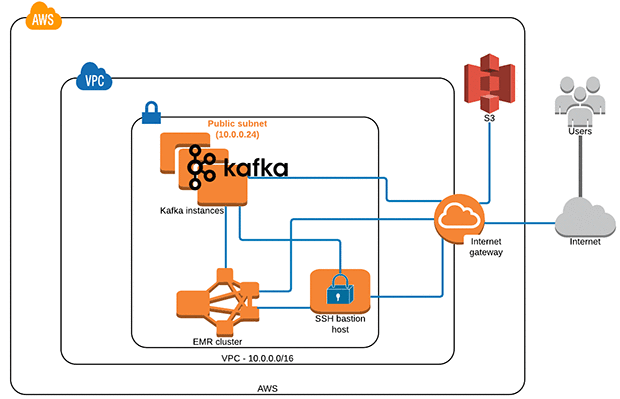
Real Time Stream Processing Using Apache Spark Streaming And Apache Kafka On Aws Aws Big Data Blog

Understanding Elastic Map Reduce Emr Aws Emr Twwip Com

Using Sparkr In Rstudio With Hadoop Deployed On Aws Ec2

Project Management Technology Fusion Apache Hadoop Spark Kafka Versus Aws Emr Spark Kinesis Stream
Aws World Of Bigdata

Big Data Amazon Emr Apache Spark And Apache Zeppelin

Aws Emr Spark S3 Storage Zeppelin Notebook Youtube

Apache Spark Architecture Explained In Detail

Setting Up Apache Spark On Aws Simba Technologies

Best Practices For Using Apache Spark On Aws

Apache Spark On Amazon Emr By Dr Peter Smith Principal Software By Peter Smith Build Galvanize Medium

Using Spark Sql For Etl Aws Big Data Blog
Apache Spark Architecture Distributed System Architecture Explained Edureka
1

Different Ways To Manage Apache Spark Applications On Amazon Emr

Getting Started With Apache Zeppelin On Amazon Emr Using Aws Glue Rds And S3 Part 1 Programmatic Ponderings

Running Apache Spark On Aws By Mariusz Strzelecki By Acast Tech Blog Acast Tech Medium

Project Management Technology Fusion Apache Hadoop Spark Kafka Versus Aws Emr Spark Kinesis Stream

Sharpen Your Skill Set With Apache Spark On The Aws Big Data Blog Aws Big Data Blog

The Bleeding Edge Spark Parquet And S3 Appsflyer
Q Tbn And9gctszupmtczb5lbhcifgv6gbx96l2345tv7zasaouovtzlrbb Du Usqp Cau
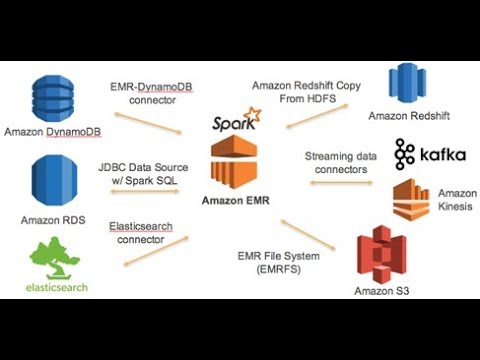
Run Spark Application Scala On Amazon Emr Elastic Mapreduce Cluster Youtube

Will Spark Power The Data Behind Precision Medicine Aws Big Data Blog

Hadoop And Spark Cluster On Aws Emr
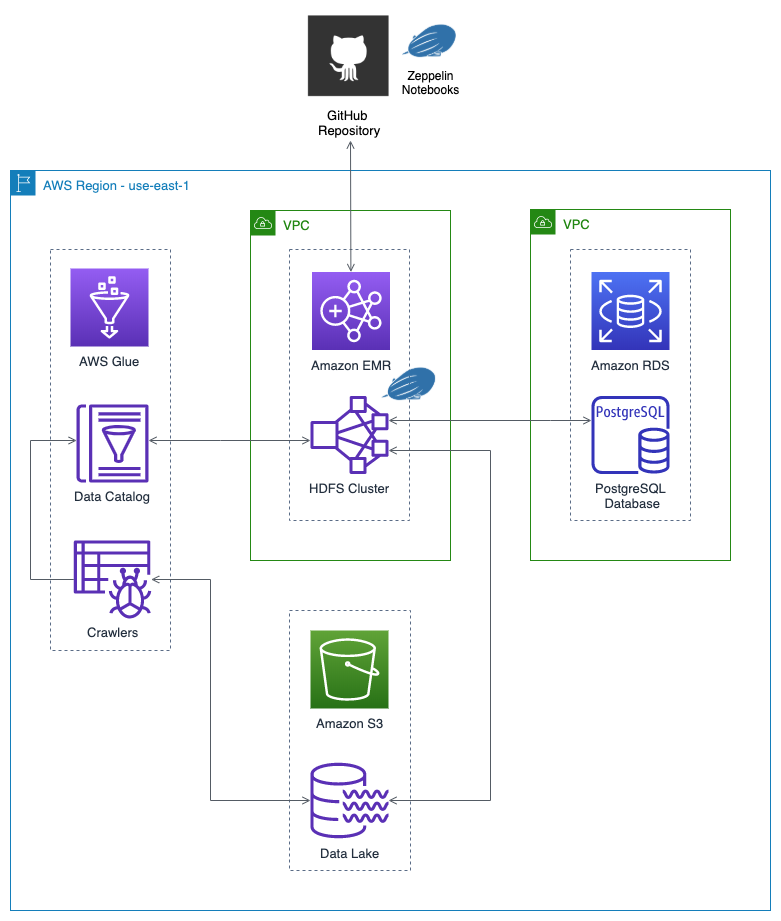
Getting Started With Apache Zeppelin On Amazon Emr Using Aws Glue Rds And S3 Part 1 Programmatic Ponderings

Aws Emr Spark On Hadoop Scala Anshuman Guha
1
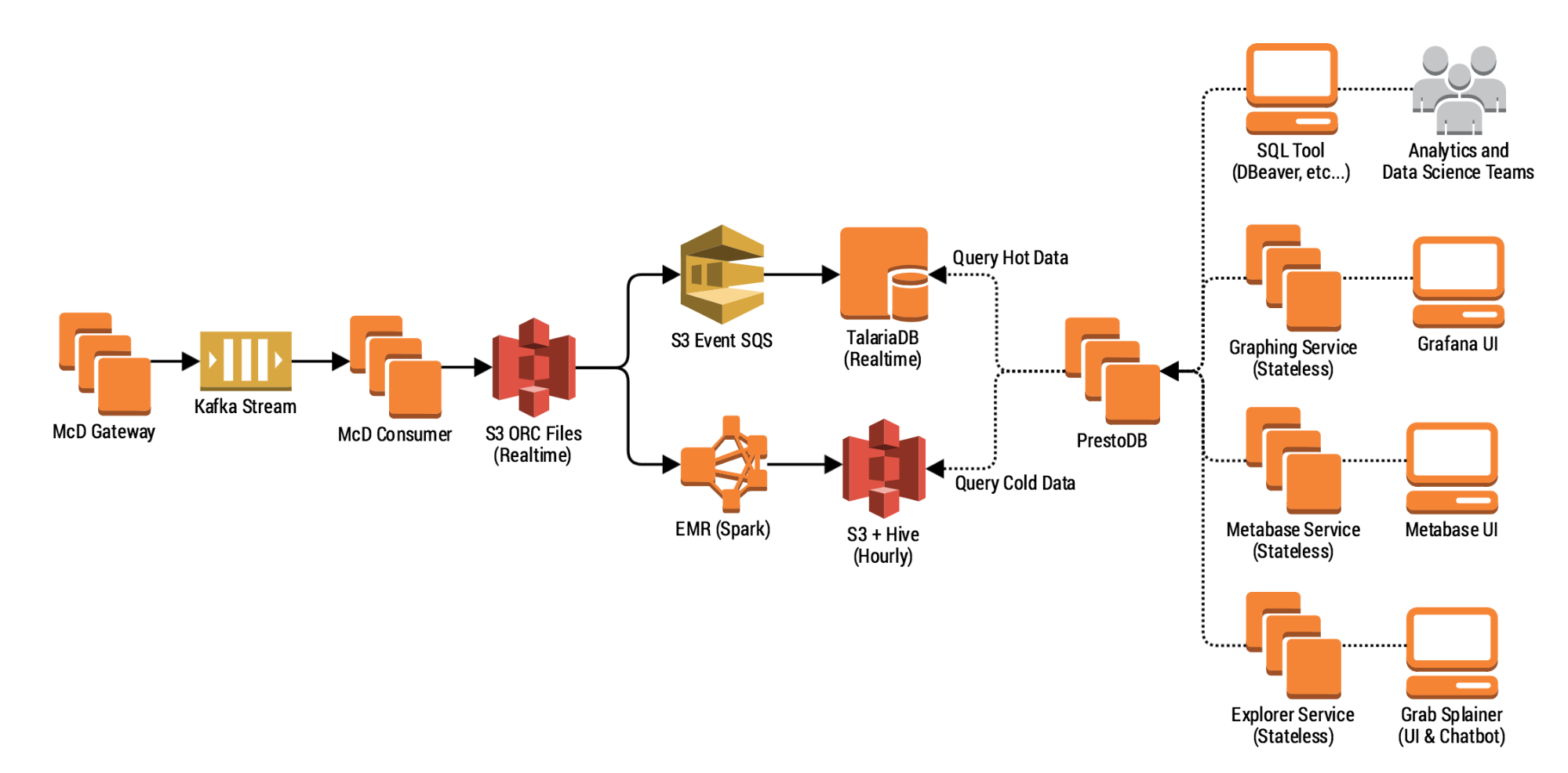
A Lean And Scalable Data Pipeline To Capture Large Scale Events And Support Experimentation Platform
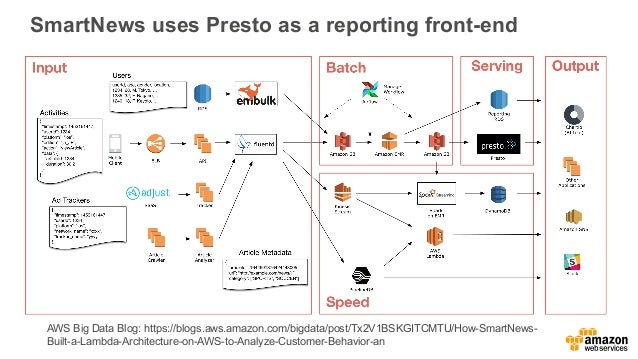
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop

Administration Streamanalytix
3
Aws Emr Tutorial What Can Amazon Emr Perform Dataflair
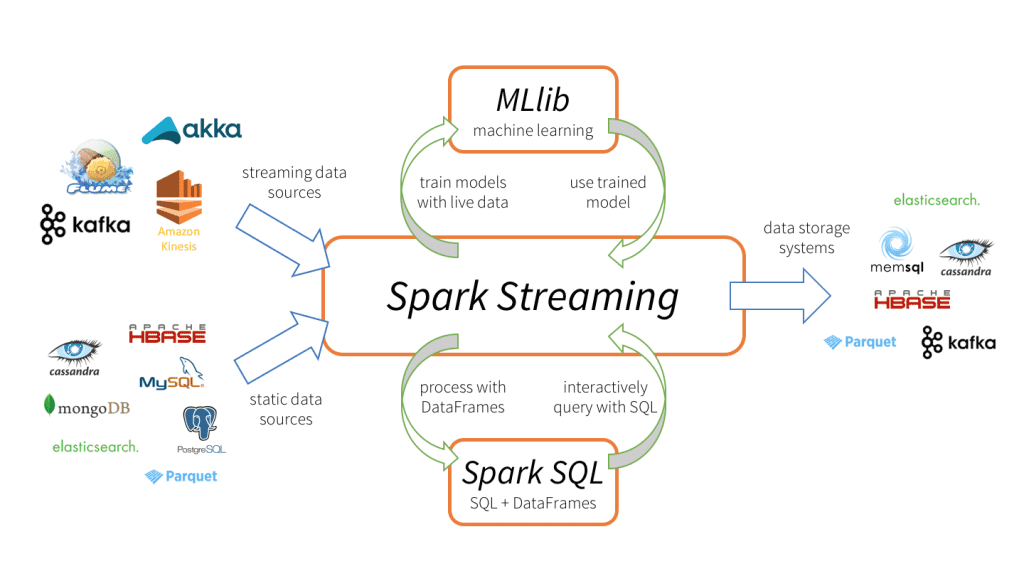
What Is Spark Streaming Databricks

Spark Development Gets Easier With Aws Emr By Seleme Topuz Medium

How To Get Hadoop And Spark Up And Running On Aws By Hoa Nguyen Insight

How Apache Spark Works Run Time Spark Architecture Dataflair

Hadoop Vs Spark A Head To Head Comparison Logz Io
Part 2 How To Create Emr Cluster With Apache Spark And Apache Zeppelin Confusedcoders
Apache Spark What Is Spark
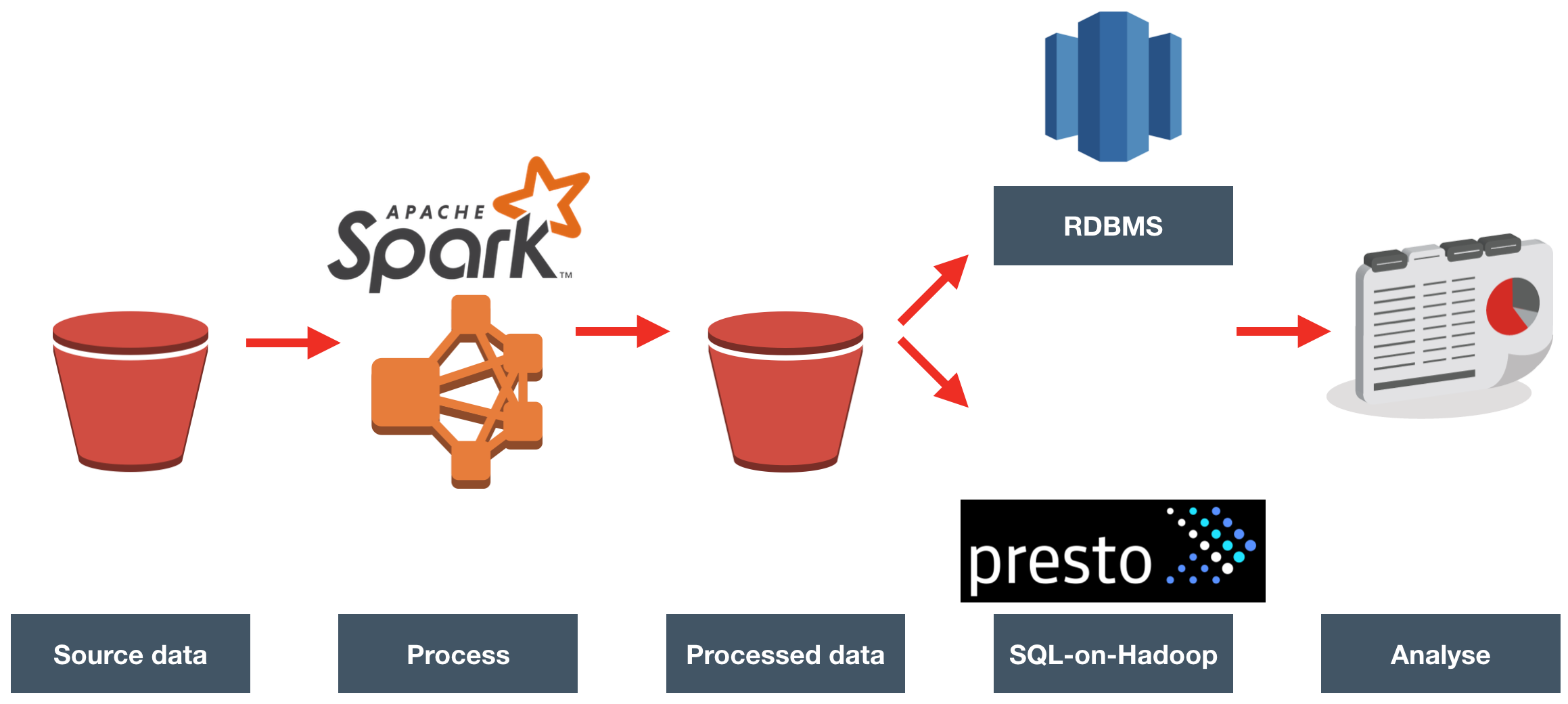
Etl Offload With Spark And Amazon Emr Part 5 Summary
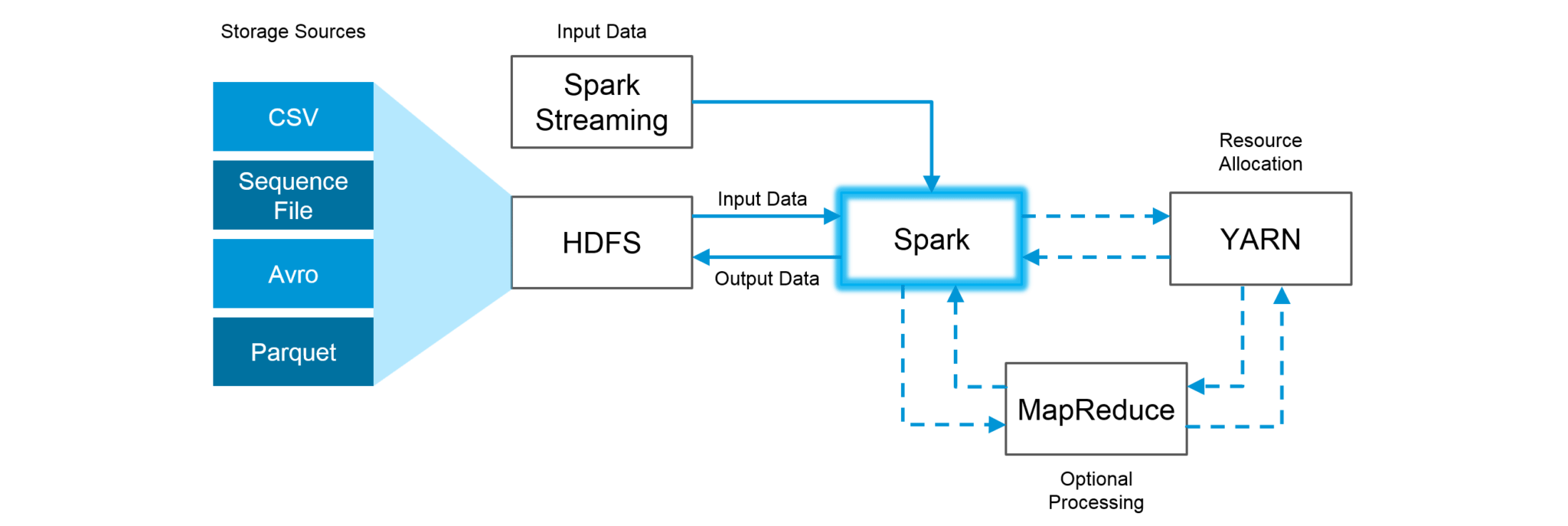
Top 55 Apache Spark Interview Questions For 21 Edureka
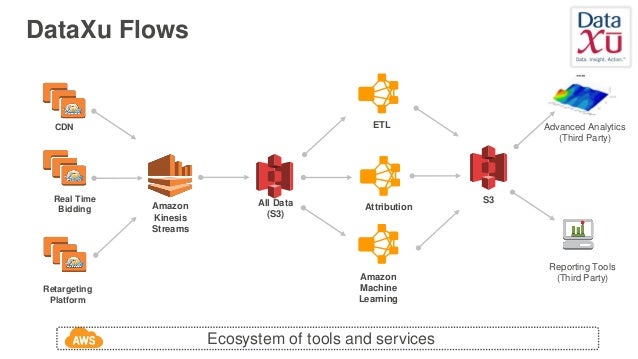
Aws Re Invent 16 Best Practices For Apache Spark On Amazon Emr
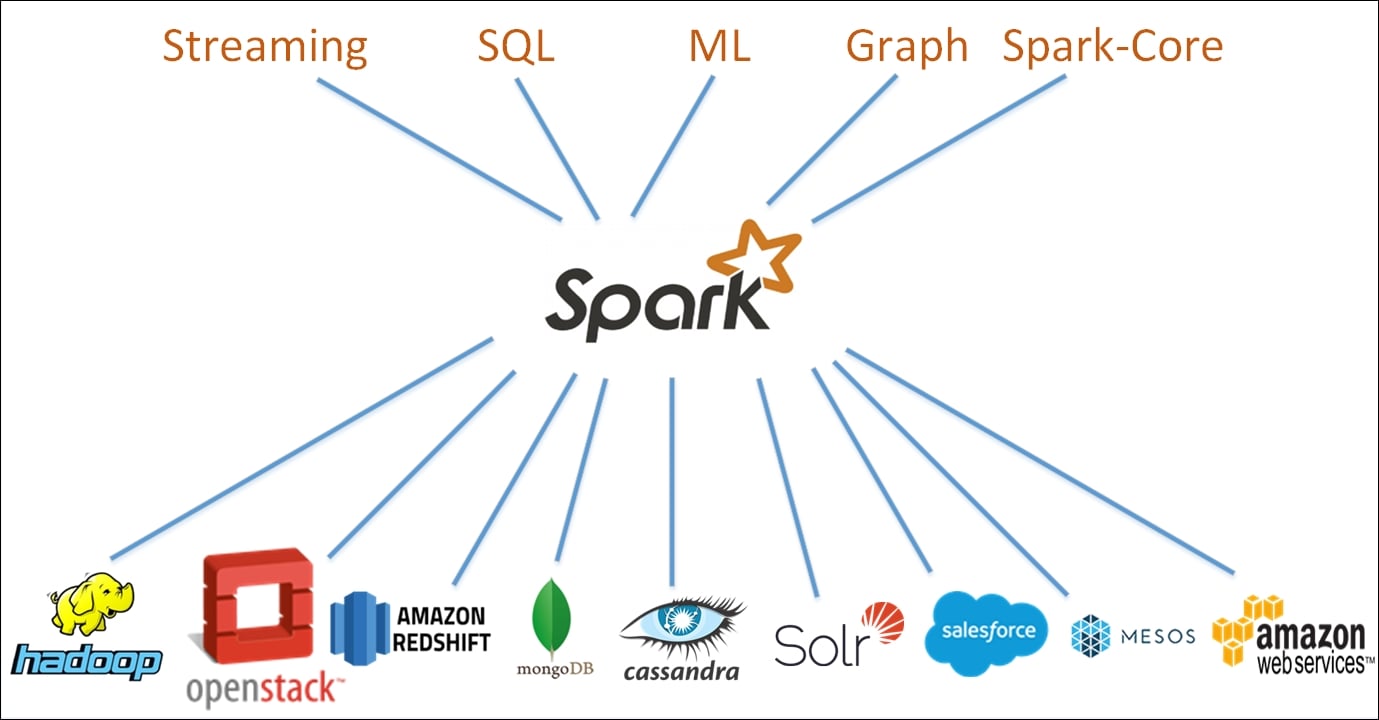
Apache Spark Architecture Overview Learning Apache Spark 2

Integrating Your Central Apache Hive Metastore With Apache Spark On Databricks The Databricks Blog

Be Your Hadoop Spark Aws Scala And Java Expert By Csgeek

Apache Spark And The Hadoop Ecosystem On Aws
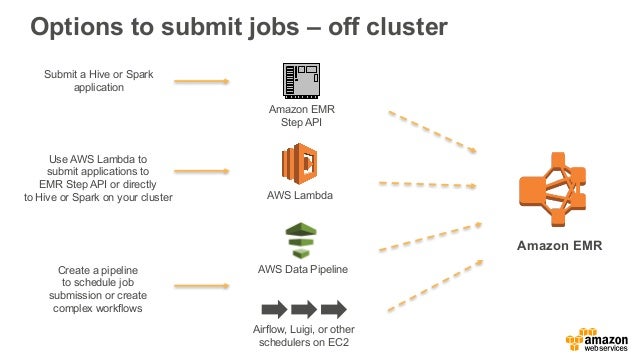
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop
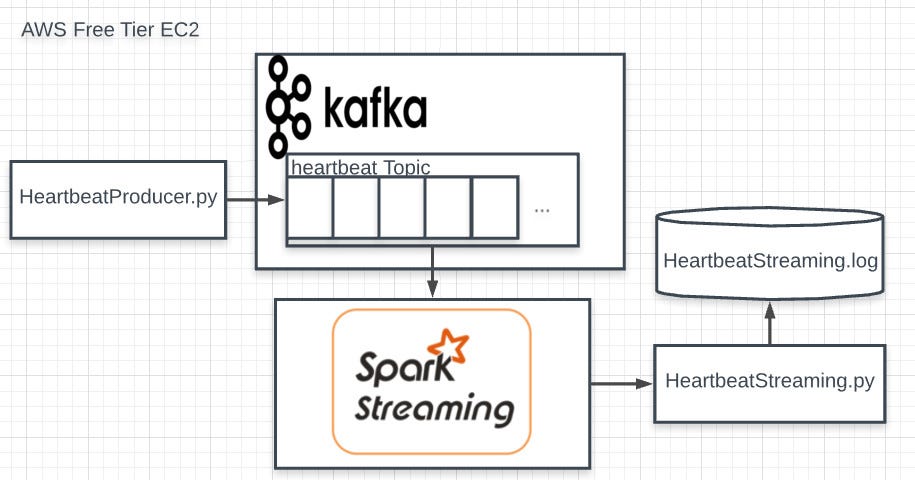
Kafka Apache Spark Streaming Example On Aws Free Tier By Waldecir Faria Medium
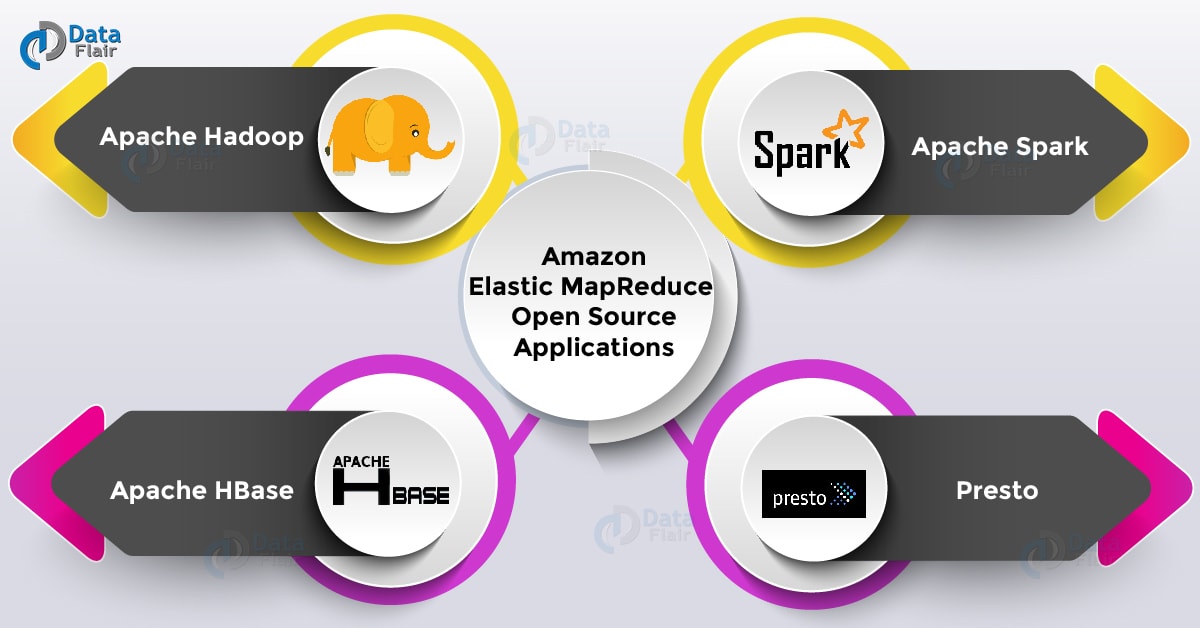
Aws Emr Tutorial What Can Amazon Emr Perform Dataflair

Using Sparklyr With An Apache Spark Cluster
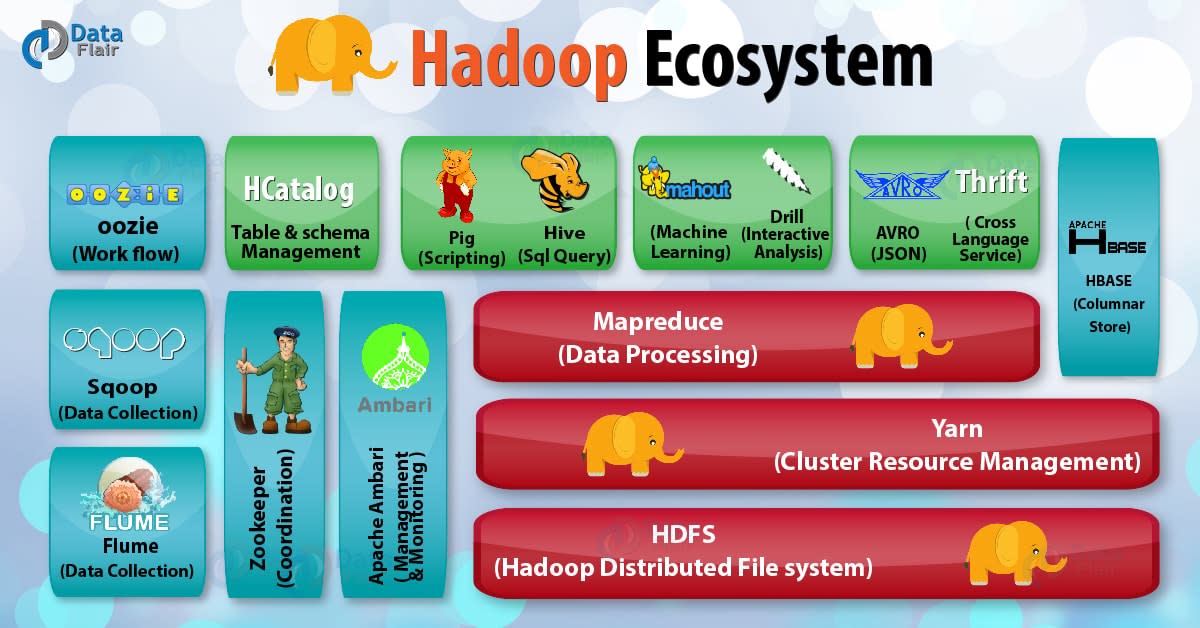
Be Your Hadoop Spark Aws Scala And Java Expert By Brainbit

Big Data Project Spark Hadoop Cloud Analytics Data Science Aws Azure Scala Facebook
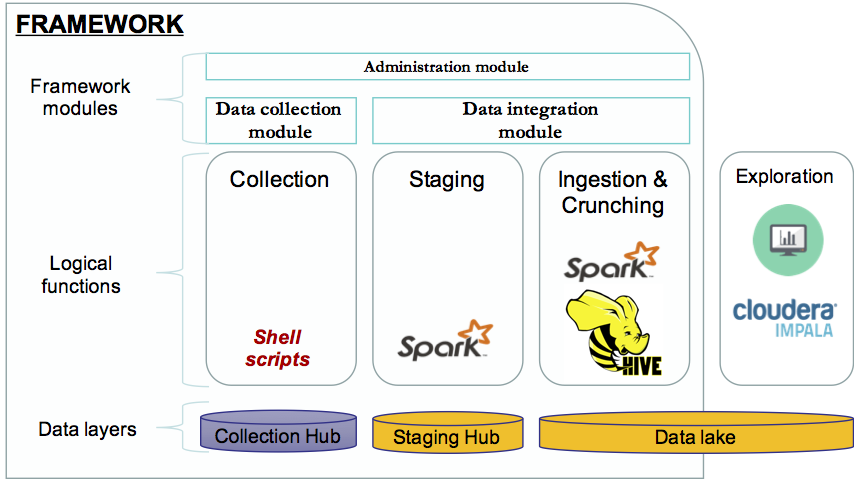
Hadoop Data Integration How To Streamline Your Etl Processes With Apache Spark

Spark Aws Big Data Blog
D1 Awsstatic Com Whitepapers Amazon Emr Migration Guide Pdf

How To Get Hadoop And Spark Up And Running On Aws By Hoa Nguyen Insight

Using Sparklyr With An Apache Spark Cluster
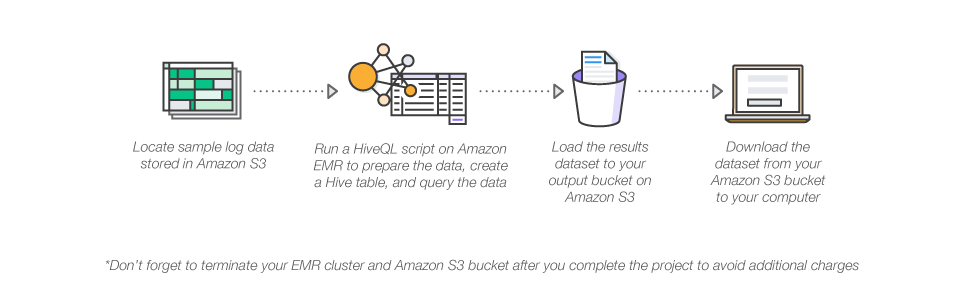
How To Analyze Big Data With Hadoop Amazon Web Services Aws
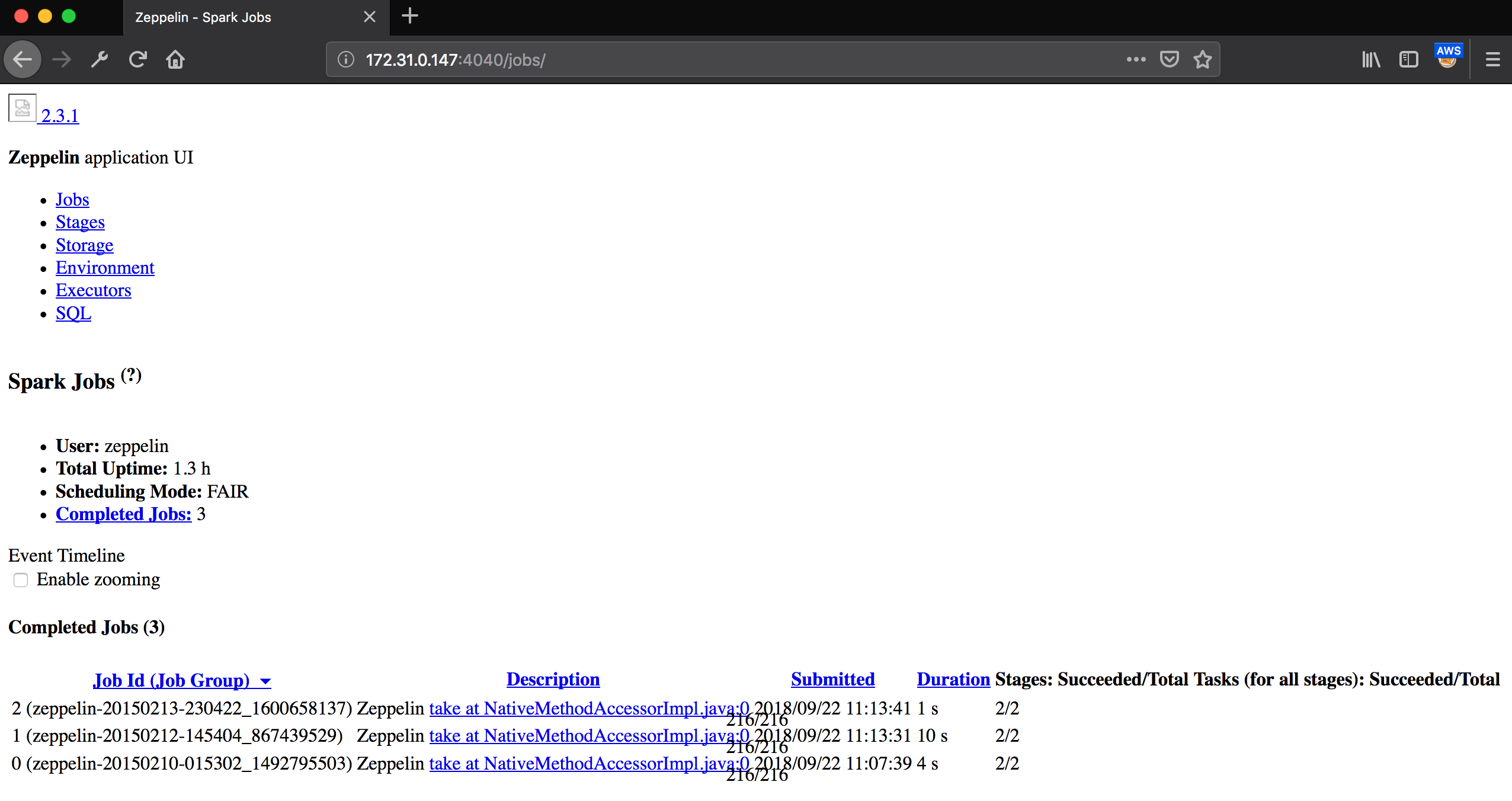
Apache Spark Web Ui On Amazon Emr

Using Oracle Data Integrator Odi With Amazon Elastic Mapreduce Emr A Team Chronicles

Big Data On Cloud Hadoop And Spark On Emr Kaizen
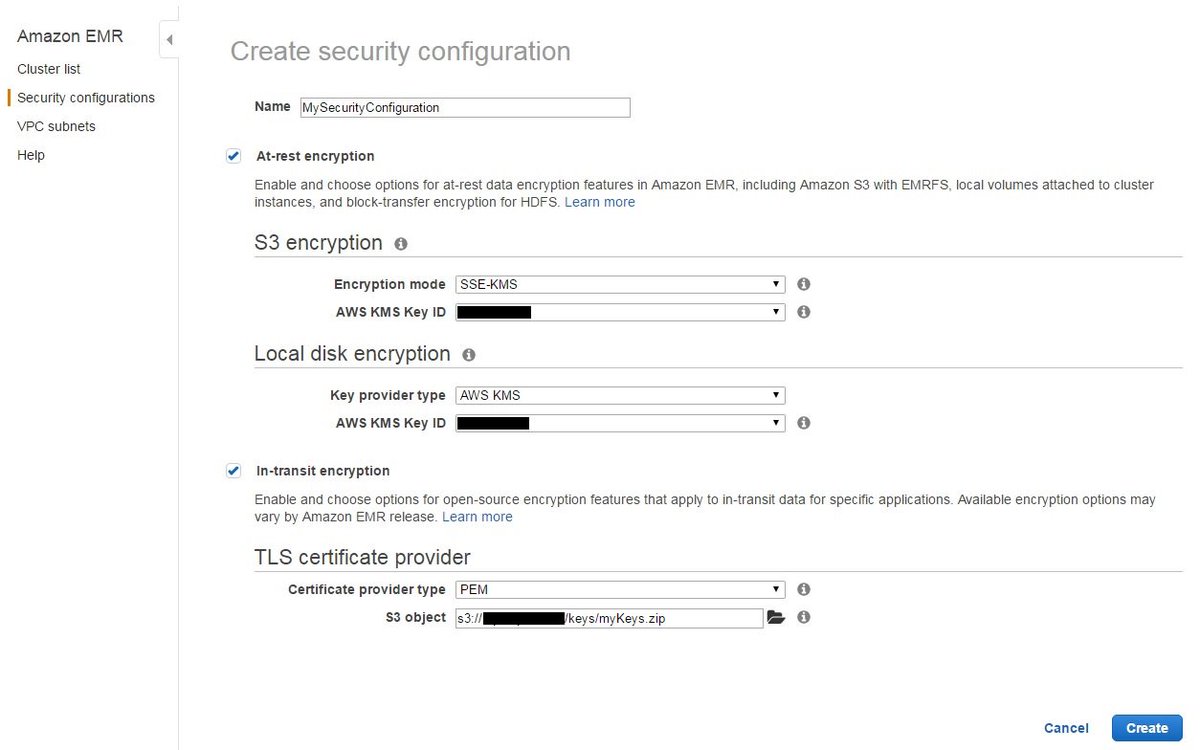
Amazon Web Services Now Enable Encryption For Apache Spark Hadoop On Emr Using Security Configurations T Co Loxa9dreey

Tuning My Apache Spark Data Processing Cluster On Amazon Emr
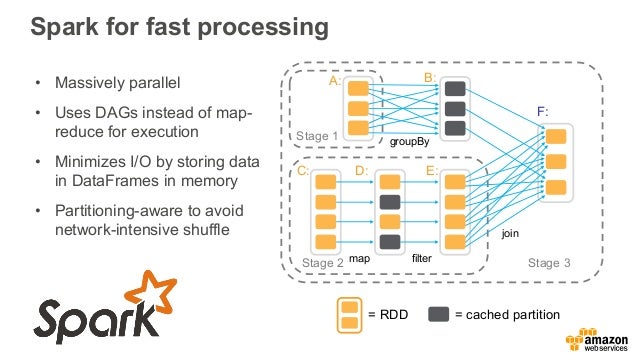
Apache Hadoop And Spark On Aws Getting Started With Amazon Emr Pop

Big Data On Cloud Hadoop And Spark On Aws Introduction Youtube

Aws Re Invent 18 Hadoop Spark To Amazon Emr Architect It For Security Governance Ant312 Youtube
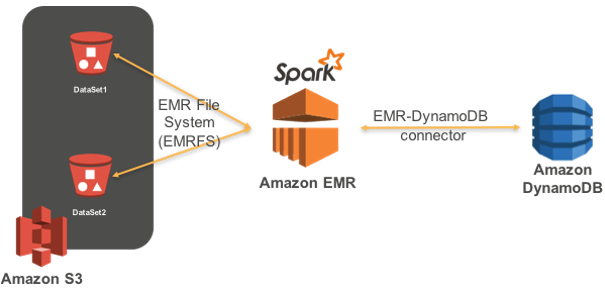
Using Spark Sql For Etl Aws Big Data Blog
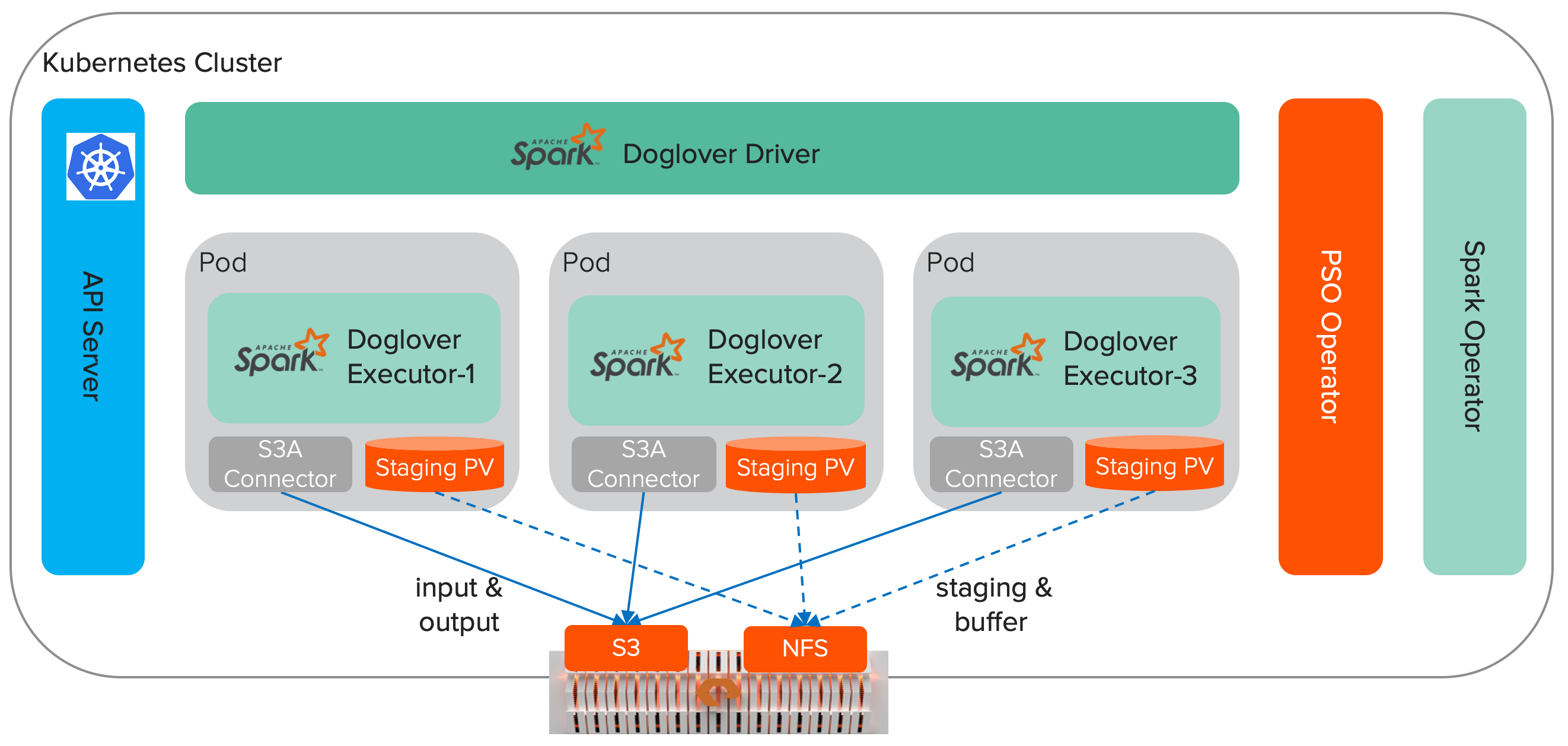
Apache Spark With Kubernetes And Fast S3 Access By Yifeng Jiang Towards Data Science

Hadoop Spark Python Scala Dataproc Aws S3 Data Lake Glue Athena Machine Learning Trough A Real World Use Case Spark Program Big Data Basic Programming

Using Hadoop And Spark With Aws Emr
New Apache Spark On Amazon Emr Aws News Blog

Optimize Downstream Data Processing With Amazon Kinesis Data Firehose And Amazon Emr Running Apache Spark Aws Big Data Blog

Upload Your Spark App To An Aws Cluster Via A Simple Python Script

Hadoop Vs Spark Debunking The Myth Gigaspaces

End To End Distributed Ml Using Aws Emr Apache Spark Pyspark And Mongodb Tutorial With Millionsongs Data By Kerem Turgutlu Towards Data Science
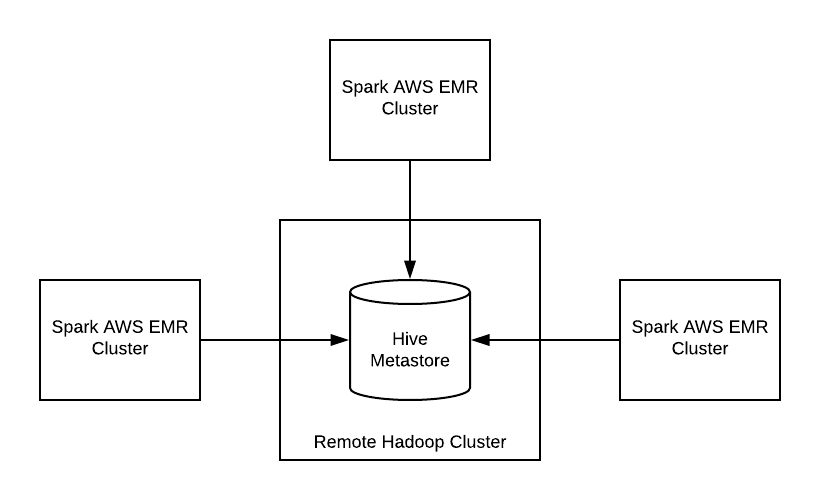
Running Spark Sql Applications With A Remote Hive Cluster
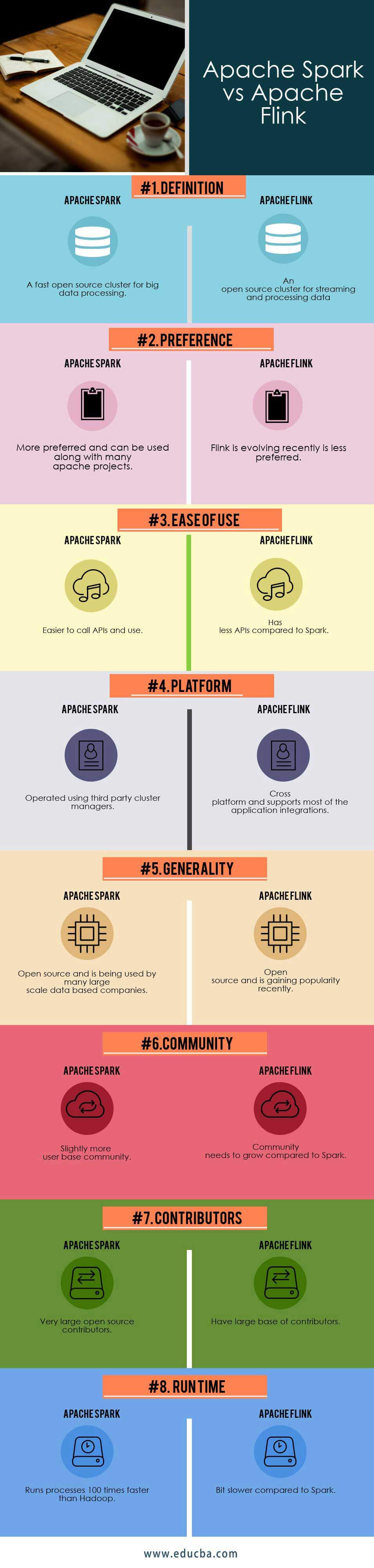
Apache Spark Vs Apache Flink 8 Useful Things You Need To Know

Apache Spark Working With Distributed Machine Learning Course

Orchestrate Apache Spark Applications Using Aws Step Functions And Apache Livy Aws Big Data Blog

Apache Spark Vs Amazon Redshift Which Is Better For Big Data



